







随着AI大模型赛道进入“深水区”,苹果智能(AI)选择中国 AI 大模型合作一事引发关注。
12月19日消息,有报道称,苹果正在和腾讯、字节跳动商谈,将两家公司的 AI 模型混元(元宝)、豆包大模型整合到在中国销售的 iPhone 设备中,但谈判仍处于早期阶段。在此之前,苹果 AI 与百度合作消息不胫而走,但如今却说明两家企业合作存在一定阻碍。
对此,腾讯方面“不予置评”,18日钛媒体AGI曾向字节跳动旗下火山引擎总裁谭待询问相关议题,他回应称,“国内安卓手机份额比苹果更高”,并未进一步直接回应此事。
值得一提的是,12月19日,北京智源人工智能研究院(智院研究院)发布国内外100余个开源和商业闭源模型多份评测结果,作为今年英伟达全球第二大买家、拥有23万张GPU的字节跳动豆包大模型名列前茅,语言模型结果字节跳动的豆包Pro、百度ERNIE 4.0 Turbo模型位居第一、第二;视觉语言模型方面,OpenAI GPT-4o与刚刚发布的豆包·视觉理解模型Doubao-Pro-Vision位列第一和第二名,能力位列第一梯队,远超大模型“六小虎”、百度、腾讯等公司研发的多款 AI 大模型。
“字节豆包太猛了,无论是投入还是自身(流量)资源,这给大模型‘六小虎’(智谱、百川、零一、月之暗面、MiniMax、阶跃星辰)带来很大压力。”一家AI大模型公司内部人士告诉钛媒体AGI现有看法。
在OpenAI o1大模型压力下,互联网大厂发力 AI 大模型技术和商业化,已经对 AI 行业造成一定承压。
对此,19日下午,智源研究院副院长兼总工程师林咏华对钛媒体AGI表示,字节豆包、快手在大模型能力上的优势有两方面:一是语言模型本身要不断的“数据飞轮”进行训练,而大厂有天然、很强的流量优势,无疑模型能力更强,尤其是主观评测上;第二,文生图、文生视频模型领域,字节、快手的优势在于高质量短视频数据层面,相比非互联网厂商有明显优势。
林咏华强调,未来大模型平台会分化成两类,即“基础通用大模型”和“智能体应用平台”。在这其中,通用基座模型具有一定的投资挑战,需要更多资源,而国内有实力的机构包括阿里通义千问、清华系企业(智谱、月之暗面等),上海AI Lab等都在持续迭代底层模型平台,这对于AGI发展十分重要。
截至12月19日收盘,百度(9888.HK)跌4.16%,腾讯(0700.HK)涨2.27%。
字节豆包、腾讯混元后发先至,苹果在考验中国大模型技术
苹果公司正对字节跳动、腾讯、百度等公司展开一场全面的审视,着重考验中国 AI 大模型技术实力,并从 “舆论场” 中进行筛选评估。
据路透12月19日报道,苹果公司正与腾讯、字节跳动就将其人工智能模型整合到在中国销售的iPhone中进行谈判,但相关讨论尚处于非常早期的阶段。
在此之前,苹果公司曾尝试与百度进行合作,积极探索通过百度“文心一言”大模型来为中国用户引入AI功能。不过,双方的合作并非一帆风顺,有报道称,苹果为国行版iPhone适配百度大模型时遇到了诸多问题,比如AI在常见使用场景中,就无法给出准确的回应。
事实上,本月苹果开始在其设备中推广OpenAI的ChatGPT,作为Apple Intelligence产品的一部分,该产品允许Siri语音助手利用该聊天机器人的专业知识,包括处理用户关于照片和文档(如演示文稿)的查询。
然而,由于ChatGPT在中国无法使用,苹果需要寻求本地合作伙伴以实现其 AI 功能,但苹果智能中国合作伙伴持续发生变化。一旦苹果iPhone能内置字节跳动的“豆包”、腾讯的“混元”大模型技术的话,会对这两家公司 AI 业务发展具有很重要的影响。
今年3月,苹果公司财报显示,其已经拥有超过22亿台活跃的苹果设备,比去年增加近4亿台。另据摩根士丹利报告显示,Apple Intelligence功能将成为苹果设备多年升级周期的“显著催化剂”,未来两年,iPhone出货量将超过5亿部,预计2025财年、2026财年出货量分别为2.35亿、2.62亿部。
站在苹果角度看,中国 AI 大模型技术能力和投入力度是非常重要的“两环”。而在这其中,字节跳动、腾讯都拥有很强的市场竞争能力。
其中,大模型技术能力层面,字节跳动“豆包”后发先至,名列前矛。
林咏华坦言,国内 AI 大模型行业开始出现“分层”,有更多公司模型的训练能力达到“应用的可能性”;也有一些公司也在往AGI方向、往规模更大、开源方向发展。本年度两期评测当中,2024年5月大语言模型56家,到年底12月减少到46家,多模态在5月是32家,到12月增至42家。
12月19日,基于全球800多个开闭源模型,智源研究院发布最新大模型评测平台FlagEval结果,包含20多种任务,90多个评测数据集,超200万条评测题目。结果显示,主要包括语言、视觉语言、文生图、文生视频、语音语言大模型综合及专项评测等九个方面。
其中,语言模型:字节跳动Doubao-pro-32k-preview、百度ERNIE 4.0 Turbo位居第一、第二;在语言模型客观评测中,OpenAI o1-mini-2024-09-12、Google Gemini-1.5-pro-latest 位列第一、第二,阿里巴巴Qwen-max-0919、字节跳动Doubao-pro-32k-preview位居第三、第四,Meta Llama-3.3-70B-Instruct排名前五。

视觉语言多模态模型:OpenAI GPT-4o-2024-11-20与字节跳动Doubao-Pro-Vision-32k-241028先后领先于Anthropic Claude-3-5-sonnet-20241022,阿里巴巴Qwen2-VL-72B-Instruct和Google Gemini-1.5-Pro紧随其后。
文生图多模态模型:腾讯Hunyuan Image位列第一,字节跳动Doubao image v2.1、Ideogram 2.0分居第二、第三,OpenAI DALL·E 3、快手可图次之。
文生视频多模态模型:快手可灵1.5(高品质)位列第一,字节跳动即梦 P2.0 pro、爱诗科技PixVerse V3、MiniMax 海螺AI、Pika 1.5排名第二至第五名。
语音语言模型:专项评测结果显示,阿里巴巴Qwen2-Audio位居第一,香港中文大学&微软WavLLM、清华大学&字节跳动Salmon位列第二、第三,Nvidia Audio-Flamingo,MIT & IBM LTU均进入前五。
K12学科测验:综合得分相较于半年前提升了12.86%,而在英语和历史文科试题的表现上,已有模型超越了人类考生的平均分,整体来说,阿里、OpenAI、阶跃星辰模型表现不俗。
此外,FlagEval大模型角斗场,是智源研究院今年9月推出的面向用户开放的模型对战评测服务,共有29个语言模型、16个图文问答多模态模型、7个文生图模型、14个文生视频模型参评,最终OpenAI、快手、字节跳动、腾讯的大模型排名前列;模型辩论平台FlagEval Debate方面,Anthropic Claude-3-5-sonnet-20241022、零一万物Yi-Lighting、OpenAI o1-preview-2024-09-12为前三名;金融量化交易评测结果显示,深度求索 Deepseek-chat,OpenAI GPT-4o-2024-08-06,Google Gemini-1.5-pro-latest位列前三。

很显然,与美国OpenAI的竞争中,从模型层,到软硬件协同推进,字节跳动已站稳 AI 大模型头部地位。
今年11月的全球月活跃排行榜上,豆包App的MAU(月活跃用户数)接近6000万,仅次于OpenAI的ChatGPT,位列全球第二;截至目前,豆包大模型日均tokens使用量超过4万亿,发布7个月以来增长超过33倍。
12月18日,火山引擎总裁谭待宣布,豆包视觉理解模型输入价格仅为0.003元/千tokens,1块钱可处理284张720P的图片,比行业价格便宜85%。
谭待对钛媒体AGI披露,目前国内安卓手机大部分都在和豆包合作,对手机厂商来说,会在某些场景用豆包,某些场景用其他的大模型,或者某一个场景混合使用,对企业用户来说,肯定也需要一个多云或者多模型的策略,“最终还是能力更好、成本更低,就会用谁,这笔账就很好算。”
谭待强调,当前字节并不关注市场竞争,因为大模型市场仍处于早期阶段,更多是场景、需求是否被满足。长期来看,大模型C端和B端、虚拟和现实世界场景都应该齐头并进发展。
“这个市场还在很早期,可能千分之一刚刚开发出来。这个时候其实不用关心竞争的问题,需要关心的是用户的需求有哪些还没有被满足。”谭待表示,最关键的是能不能把东西做好,把方案的落地应用做好,“我们有时候跟客户说,你每家都试试看,然后就知道跟谁来做,这是一个很自然的现象,而且也不涉及话语权高和低的问题。”
林咏华表示,2024年下半年,AI 大模型发展更聚焦综合能力提升与实际应用,多模态模型发展迅速,涌现了不少新的厂商与新模型,语言模型发展相对放缓。同时,得益于文本大模型的进步,语音语言模型能力提升巨大,覆盖面更全,但在具体任务上与专家模型还存在一定差距,整体而言,性能好、通用能力强的开源语音语言模型偏少。
林咏华强调,部分 AI 大模型公司已经转向了Agent应用层方向,未来如果提高效率、形成更广泛应用的话,需要AI公司在推理端发力。
OpenAI CEO奥尔特曼(Sam Altman)曾断言:“我们会有越来越好的模型,但我认为下一个巨大突破将是AI Agent智能体。”
今年采购46万张GPU卡,AI 大模型企业加速“内卷”投入
除了技术能力,字节跳动、腾讯仍在“卷”算力,两家共计买了46万张英伟达GPU芯片,成为英伟达全球第二大买家。要知道,今年英伟达总销售数量才达到200万张AI GPU计算卡。
具体来说,研究机构Omdia报告显示,微软今年采购了约48.5万片英伟达Hopper 架构的H100/H200 GPU计算卡,是其2023年购买的同代英伟达 AI 处理器数量的三倍多,并列排名第二是两家中国公司——字节跳动、腾讯,都分别采购约23万片英伟达GPU芯片,超越Meta、亚马逊和谷歌等美国科技巨头。
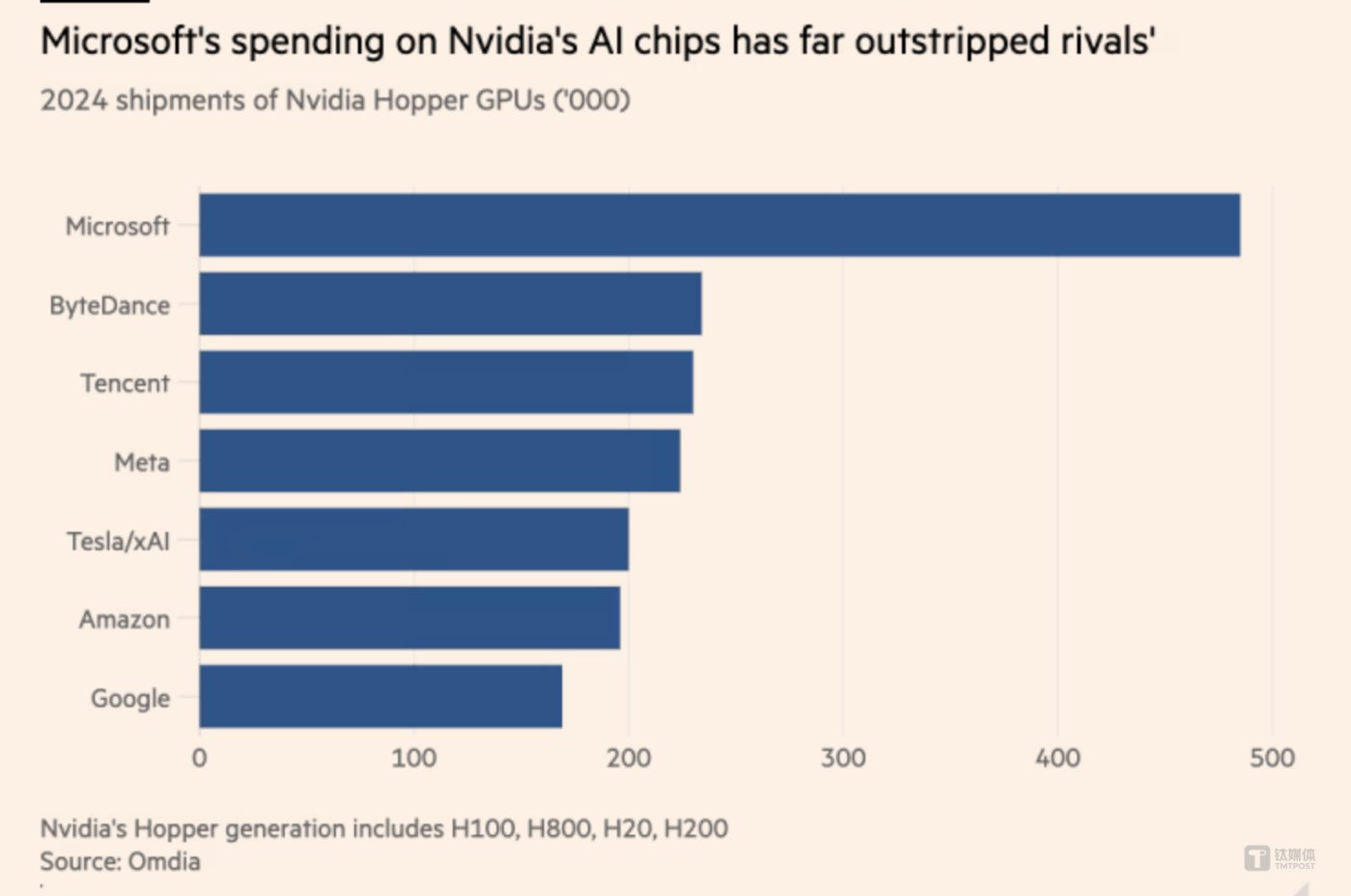
上述报告显示,到2024年,全球科技公司将在服务器上花费约2290亿美元,其中微软的资本支出310亿美元,亚马逊的资本支出260亿美元,数据中心基础设施前十大买家投资占比达60%。
Omdia云计算和数据中心研究总监Vlad Galabov表示,到2024年,服务器支出规模约43%将流向英伟达,“我们已经接近峰值了。”
微软Azure全球基础设施高级总监斯皮尔斯 (Alistair Speirs) 表示,“良好的数据中心基础设施非常复杂,是资本密集型项目,需要多年的规划。因此,预测我们的增长将在哪里,并留出一点缓冲空间,这很重要。”
谭待则认为,AI 的出现让所有的基础架构从 CPU 转向 GPU 为核心,从而使得“云原生”概念变得十分重要。“我们认为未来 10 年其实 AI 云原生是更重要的事情,未来可能从基础架构领域就是很大的变化,从云原生到 AI 云原生,火山希望做成这块的领军企业。”
谭待强调,AI大模型的场景很重要,不仅需要平台和算法,而且需要服务,帮助企业辨别AI大模型使用场景,从而做好 AI 技术落地。
林咏华指出,现在优秀、开源的语言模型已经发展到了一个基础能力水平,再出现明显的增长肯定不是特别容易,并非拼更大的参数或更多的数据,而是需要更多深入的创新能力。现在,语言模型就进入到一个“深水区”,有更大的收益、创新难度,但多模态模型层面,一些基础能力还是有明显的增长空间,因此,明年多模态模型会层出不穷。
展望未来,林咏华强调,AI 大模型“数据”并没有所谓的“耗尽”。十年前,互联网数据占全球数据量份额接近5%,如今到2021年-2024年降至1.3%,但全球使用中文上网的人数一直没变,约19%,所以巨大的互联网中文数据形成了“孤岛”,因此,打破 AI 模型训练的数据孤岛就将变得十分关键,而“合成数据”解决的是更复杂问题和方向,是一种更加高效产生数据的方式。
“目前,国内 AI 视频生成模型的表现其实与国外(sora)相差无几。”林咏华称,2025年,FlagEval评测体系的发展将进一步探索动态评测与多任务能力评估体系。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。



