





欢迎来到【AI创业日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
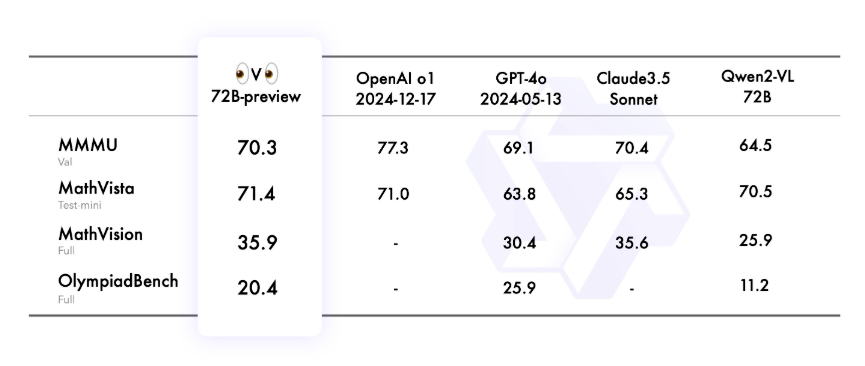
1、阿里发布多模态推理模型QVQ-72B!视觉、语言能力双提升
阿里巴巴最近推出的QVQ-72B多模态推理模型在语言和视觉能力上实现了显著提升,能够处理复杂的推理和分析任务,尤其在多步推理和数学推理方面表现突出。该模型的出现标志着阿里巴巴在多模态AI领域的重大突破,提供了新的工具和思路来解决复杂问题,推动各行业的智能化升级。
2、投资三家机器人公司后 OpenAI欲自研人形机器人
OpenAI正在积极探索自研人形机器人,尽管曾在2021年关闭机器人部门。近期,该公司通过投资三家机器人公司,显著布局机器人领域。其旗舰模型O3在AGI测试中首次超越人类水平,为进军实体机器人提供了技术支持。然而,进入这一竞争激烈的市场,OpenAI可能面临利益冲突和硬件研发短板等挑战。
3、QQ音乐14.0版本上线,发布首个AI大模型音效、智能匹配听歌音效
QQ音乐14.0版本的推出标志着音乐体验的一个新高度,特别是引入的AI大模型音效。这一创新技术通过分析音频特征,为用户提供个性化的听觉体验,尤其在3D环绕音效方面表现出色。此外,伴唱功能的升级使得用户可以根据个人需求调节播放速度和音调,进一步增强了音乐互动的乐趣。
4、讯飞星火浏览器插件新升级 新增翻译总结、继续提问等AI功能
讯飞开放平台最近对其星火浏览器插件进行了重要升级,显著提升了用户的浏览体验和工作效率。新功能包括支持多语言的全局翻译、增强的网页总结能力以及“继续提问”功能,使用户能够深入讨论并获取更高质量的答案。此外,插件还提供了一键朗读功能,帮助用户提高外语口语水平。
5、字节开源 Midscene.js:AI驱动的E2E测试框架迎来突破
随着人工智能技术的迅猛发展,E2E测试领域正经历着一场创新的革命。字节跳动的web-infra团队推出的Midscene.js,结合多模态大语言模型,极大地简化了用户界面测试的过程。用户无需编写代码,通过自然语言即可与网页进行交互,提升了测试效率。
6、DeepMind项目MegaSaM :输入普通视频即可预估相机视角和景深
MegaSaM系统的推出标志着计算机视觉领域的一次重大突破。该系统能够从普通动态视频中快速、准确地估计相机参数和深度图,克服了传统技术在动态场景中的局限性。通过对深度视觉SLAM框架的创新性修改,MegaSaM在复杂环境下的实时处理能力显著提高,实验结果显示其在准确性和效率上均优于以往技术。
7、字节TikTok算法负责人陈志杰或将离职,投身AI Coding方向创业
字节跳动的TikTok算法负责人陈志杰即将离职,计划专注于AI Coding领域的创业。自2022年加入字节跳动以来,他负责TikTok的推荐算法和数据科学团队,之前在百度积累了近九年的技术经验。随着AI Coding市场的快速发展,预计到2032年将超过295亿美元,吸引了众多投资者的关注。
8、Fireworks AI推出文档解析神器!AI轻松读懂复杂文件
Fireworks AI最近推出了“Document Inlining”功能,旨在解决处理非结构化文档的难题。该功能能够将PDF、截图和图像等文档转化为大语言模型可理解的结构化文本,显著提高了AI处理文档的效率和准确性。其核心在于强大的复合AI系统,能够自动识别和解析多种内容,操作简单且兼容OpenAI API,用户无需额外学习成本。
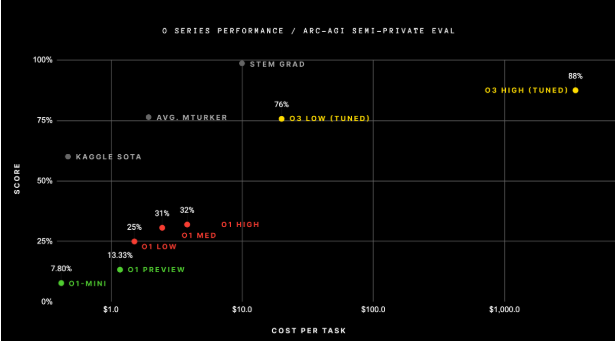
9、果然最强!OpenAI 新模型o3在ARC-AGI基准测试得分破纪录
OpenAI最新发布的模型o3在ARC-AGI基准测试中取得了显著成绩,标准计算条件下得分75.7%,高计算版本更是达到87.5%。尽管这一成就震惊了AI研究界,但专家指出o3仍未达到通用人工智能(AGI)的标准。o3的计算成本高昂,解决每个谜题需17至20美元,且在某些简单任务上表现不佳。
10、打错字也能 “越狱”GPT-4o、Claude:揭秘AI聊天机器人的脆弱性!
最近的研究揭示了先进AI聊天机器人在面对简单拼写错误时的脆弱性。通过一种名为“最佳选择(Best-of-N,BoN)越狱”的算法,研究人员发现,故意加入拼写错误可以让这些模型忽视安全防护,生成本应拒绝的内容。这一发现不仅突显了AI与人类价值观对齐的困难,也表明即使是高级AI系统也容易受到欺骗。
11、尴尬!谷歌被曝用Claude模型进行对比测试来改进Gemini AI
近日,谷歌的Gemini人工智能项目正在通过与Anthropic公司的Claude模型进行对比测试,以提升自身的性能。负责Gemini改进的承包商正在评估这两种模型的输出,比较的标准包括真实性和安全性。尽管谷歌是Anthropic的主要投资者之一,但谷歌发言人表示并未对Gemini进行Claude模型的训练。
12、研究发现,OpenAI 的 o1-preview 在诊断复杂医疗病例方面优于医生
一项新研究表明,OpenAI 的 o1-preview 人工智能系统在复杂医疗案例的诊断上表现优于人类医生,达到了88.6%的准确率。该系统在医疗推理方面同样出色,获得了80个病例中78个满分。尽管o1-preview在某些方面表现优秀,但在实际应用中仍面临高成本和不切实际的测试建议等问题。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。





