







200名音乐人联名信抗议的消息刚出,Stability AI的新音乐工具就来了!刚刚发布的Stable Audio 2.0,可以创作长达3分钟的音乐,哼哼几句就能给你创作出一段音乐了!不过广大网友和音乐人试用后表示:有点失望……
200多名音乐人联名签公开信抗议Suno的余音还未消,AI音乐又出新工具了——
Stability AI,也下场卷AI音乐了!看来,核心开发人员的出走,并没有减慢它发布产品的步伐。
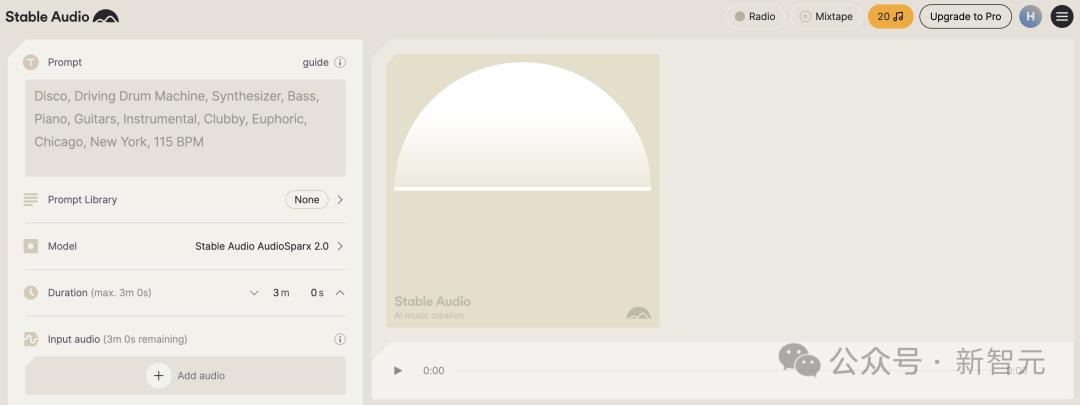
就在刚刚,Stability AI发布了Stable Audio 2.0。

仅仅用一条自然语言指令,它就能以44.1 kHz的立体声质量,创作出高质量、结构完整的音乐作品。
而且,每首曲目最长可达3分钟!相比之下,Suno最长可创作2分钟,这方面可是被Stable Audio 2完爆了。
并且,Audo 2.0的音频到音频功能,目前只有Meta的MusicGen可以做到,连Suno都做不到。
好消息:模型已经在Stable Audio官网上免费开放使用了,并且很快就能通过Stable Audio API提供服务。
顺便,再画个重点:Stable Audio做出来的音乐,是可以商用的!

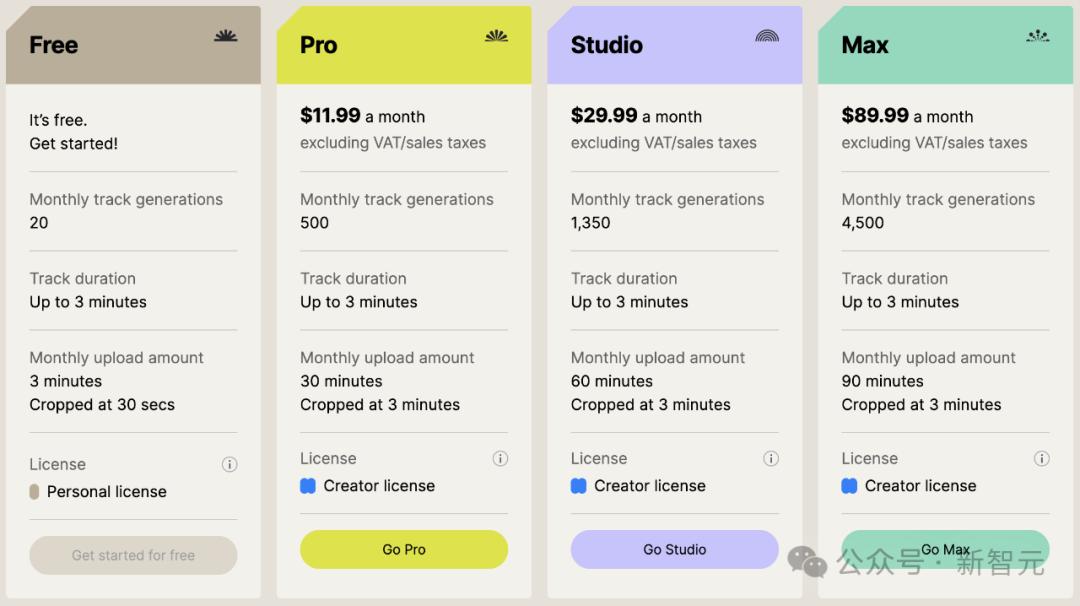
就是价格着实不便宜: Pro版11.99美元/月、Studio版29.99美元/月、顶配Max版则直接来到了89.99美元/月。
小编亲自上手「爆改」了一波周杰伦的歌。
Prompt如下——
Post-Rock, Guitars, Drum Kit, Bass, Strings, Euphoric, Up-Lifting, Moody, Flowing, Raw, Epic, Sentimental, 125 BPM
并且输入了一段《夜曲》的旋律,Audio 2.0输出的音乐是这样的。
听起来似乎不太理想。(当然,大概率是因为小编不专业导致的

)
那哼哼一首试试呢?小编哼了几句《等你下课》,传上去——
Blues, R&B woman, singer
出来的结果,跟原曲不能说是一模一样,只能说是毫不相干。
小哥一段b-box,身后仿佛一个乐队
消息一出,各位音乐人们立刻冲了!
比如这位国外小哥,自己b-box再加上Audio 2.0给配上的音乐,直接一个人干出了一个乐队的效果。
并且,无论是b-box还是完整的歌曲,都是Audio 2.0生成的。
这位日本网友,用Audio 2.0创作出了一首「东方地灵殿」风格的歌曲。
Shugo Nozaki在试用后点评道:Audio 2.0跟Suno不同,它似乎保留了简单的提示,并且把歌曲简化了。
总之,这次的模型不仅可以从文本创作音频,还能从音频创作音频。
旋律、伴奏、独立音轨、音效……没有它不会的。
完整的音轨创作
因为创作时间长达3分钟,Stable Audio 2.0能让每首作品都拥有清晰的结构,包括引言、主体和结尾部分,还能加入立体声的音效,让作品更加立体生动。
比如下面这段音乐,结构非常完整,乐曲的风格舒缓、空灵,十分解压。
A beautiful piano arpeggio grows to a full beautiful orchestral piece
而在下面这段音乐中,由钢琴旋律开始了一段忧郁的乐章,随后的管弦乐乐句,在涌动中把整个乐章推向高潮,最后逐渐回归宁静。
Piano melody begins a melancholic journey, full orchestral climax, the swells of the orchestral instrumentals
只要给出具体的prompt,就能生成完全符合要求的音乐了,只要脑海里能想象出来,它就能生成。
这感觉,简直就是在元宇宙里的虚拟工作室中玩赛博乐器!
再比如,这首127 BPM的Tech House,就融合了琶音器,Rhodes电钢琴的和弦与旋律交织出的美妙旋律。并且还包含有切分节奏的打击乐和拟声打击乐,House风格的重鼓,自然的打击乐效果,以及行走贝斯带来的流动感。
整个曲目在神秘、低调的氛围中展开,让人仿佛置身于探索未知的旅程中。
Tech House, underground UK rave, 127 BPM, synthesizer arpeggio, beautiful Rhodes piano chords and melodies, epic sweeping string section, syncopated percussion and foley percussion, house kick pattern, drum machine, natural percussion, breaks, walking bass, Mysterious, Mystical, Low-key
以及,这首125 BPM的后摇,不仅有精心录制的鼓组和电贝斯,偶尔还穿插着激昂的和声,整体给人一种宏大且高潮迭起的氛围。
Post Rock, echoing electric guitars with chorus, well recorded drum-kit, Electric Bass, occasional soaring harmonies, Moving, Epic, Climactic, 125 BPM
而这首Nu-Disco融合了放克风格的Emotional Pian和浓郁的弦乐四重奏,以及层次丰富的鼓点。此外,G-Funk贝斯和合成器的现代感,完美适合俱乐部氛围。
Nu-Disco, funky emotional Piano, lush string quartet, well layered Drum Machine, well-arranged composition, funky G-Funk bass, Synthersizers, Modern, Club-orientated, 115 BPM
好玩的是,Audio 2.0也可能生成有人声的歌词,但遗憾的是,我们并不能自己填词,只能它给什么词,我们用什么词。
这就多少差点意思了……

下面就是Gorden Sun做的一首男声流行乐。
音频转换
你脑海里有一段旋律,只要把它哼给Stable Audio 2.0,它就能给你样本直出!
旋律可以直接变成鼓、低音吉他。
或者来一段b-box,直接就变成了Lofi hip hop box。
声音变化与音效创造
这次的新模型,大幅提升了声音和音效的制作能力。
无论是模拟键盘的轻敲声、人群的欢呼声,还是城市街道的背景嗡嗡声,都能为音乐增添新的层次。
风格转换
另外,如果我们已经有了一个某风格的音频样本,想让它变成另一种风格,只要上传到Audio 2,告诉它你想要什么样的,它就自动给你生成了。
无论是音乐的整体风格,还是调整特定部分的基调,Audio 2都能为我们独家定制!
从此,艺术家和音乐制作人的创作自由度和想象力,都可以充分释放!
其实,早在2023年9月,公司就已经推出了1.0版本,成为首款商业成功的AI音乐工具。
当时,Stable Audio 1.0就被《时代》杂志评为2023年的最佳发明之一。
不过,最近闹得沸沸扬扬的音乐家抗议Suno的事件,也给音乐版权问题敲响了警钟。
Stability AI是怎么解决这个问题的呢?
对此,他们也有对应措施:Stable Audio 2.0是专门训练于AudioSparx音乐库的授权数据集上,绝对尊重退出请求,并且表示一定会为创作者提供公平的补偿。
技术原理
为何Stable Audio 2.0能创作出结构如此完整的音乐作品?
原因就在于,它采用了一种特殊设计的技术架构。
为此,研究者对系统进行了全面优化,确保它在处理长时间音频时的表现更加出色。
通过一个新型的高效压缩技术,他们将原始的音频数据压缩成了更短的格式,这样就提高了处理效率。
此外,他们还引入了一种先进的「Diffusion Transformer」技术,这种技术比之前的方法更擅长处理连续长音频数据。Stable Diffusion 3中也用到了类似技术。
这两大技术的结合,就让模型能够精准地捕捉音乐中的复杂结构,并且重现出来。
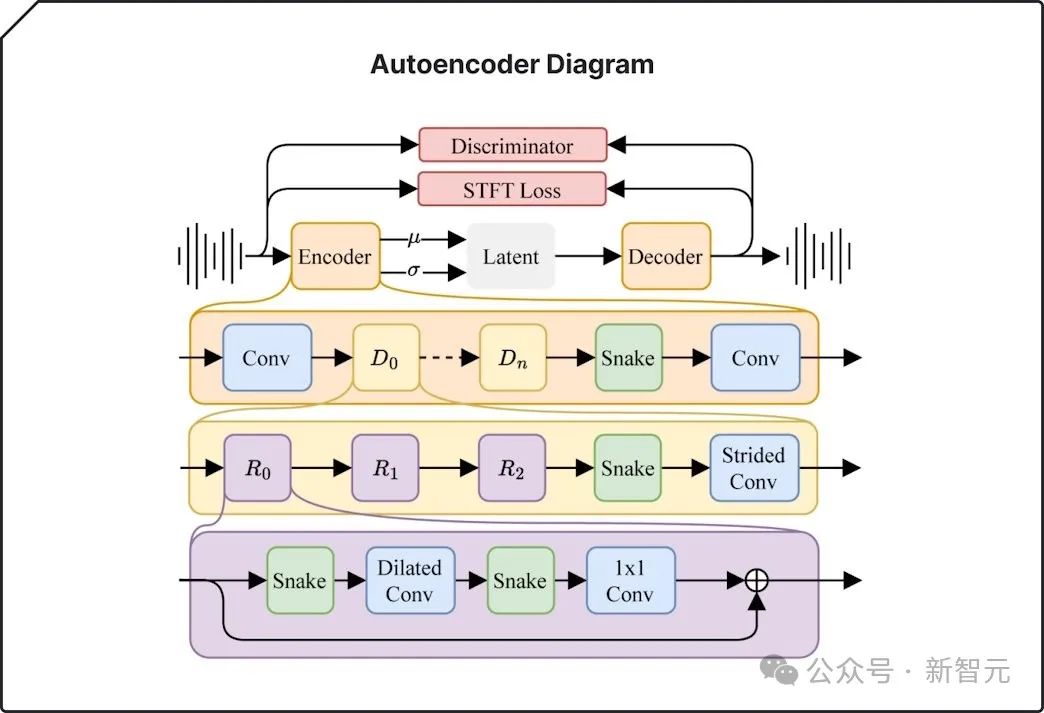
自动编码器可以压缩音频并将其重构回原始状态。它能捕捉并复制关键特征,同时过滤掉不太重要的细节,从而生成更连贯的作品。
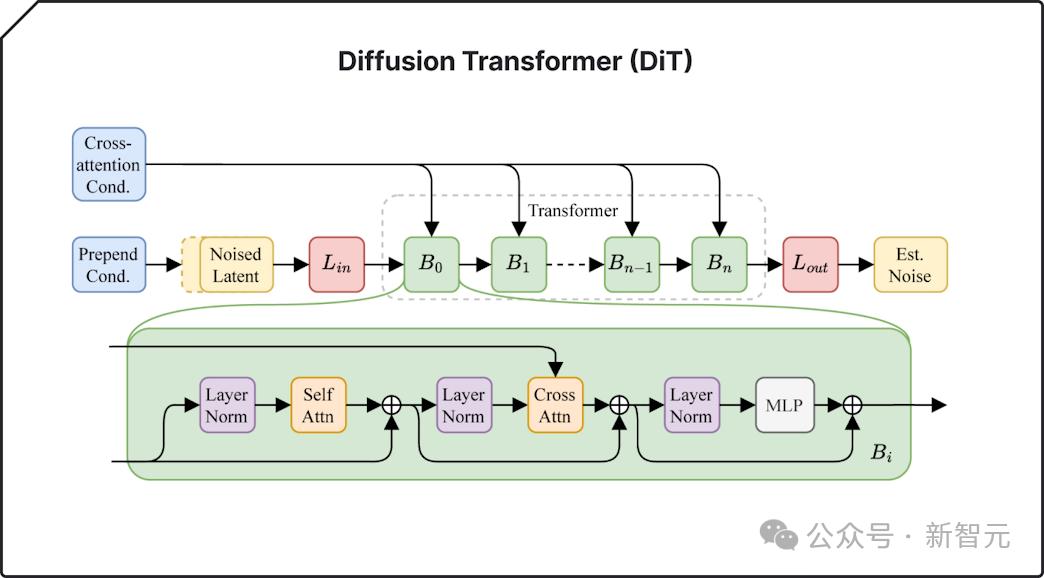
Diffusion Transformer(DiT)可以逐步将随机噪声细化为结构化数据,识别复杂的模式和关系。结合自动编码器,它获得了处理更长序列的能力,从输入中创建出更深入、更准确的解释。
训练数据
跟1.0版本一样,2.0版本也是基于AudioSparx提供的庞大音频库进行训练的。
这个音频库涵盖了超过80万个文件,内容丰富,包括各类音乐、音效以及单独乐器的音轨,并且附有相关的文本描述。
而AudioSparx平台上的所有艺术家,都有机会选择是否让自己的作品参与到Stable Audio的训练过程中。
而且,为了维护创作者的版权,Stability AI在上传音频时会与Audible Magic合作,采用他们的先进内容识别技术。
这种技术就能实时地识别和匹配音频内容,有效防止侵权,包含每一位创作者的权益。

网友吐槽:没有歌词就没有灵魂啊
虽然宣传地很炸裂,但Audio 2.0放出后,也遭到了部分网友吐槽。
最明显的问题就是,它并不能像Suno一样生成歌词。
这就仿佛抽走了一半灵魂。

也有网友吐槽说,自己并不认为这是什么好音乐。它就仿佛一张AI生成的图片,仔细观察就会发现很多错误。
在ta看来,优秀的作曲家应该因为创作出没有错误的好音乐而得到报酬,即使他们比AI更贵。
的确,有很多人表示,它的音乐质量不行,比不上Suno。

甚至很多音乐生成器都比它生成得要好。

「可是,我已经被Suno宠坏了」。

音乐APP创始人试用后:有点失望
这位名叫Ezra的音乐APP创始人在试用Audio 2.0后,则详细地记录下自己的体验。

视频地址:https://www.audiocipher.com/post/stable-audio-ai#viewer-85l4b974663
他做了以下几个实验,体验了Audio 2.0对各种音乐的生成能力。
手指鼓点
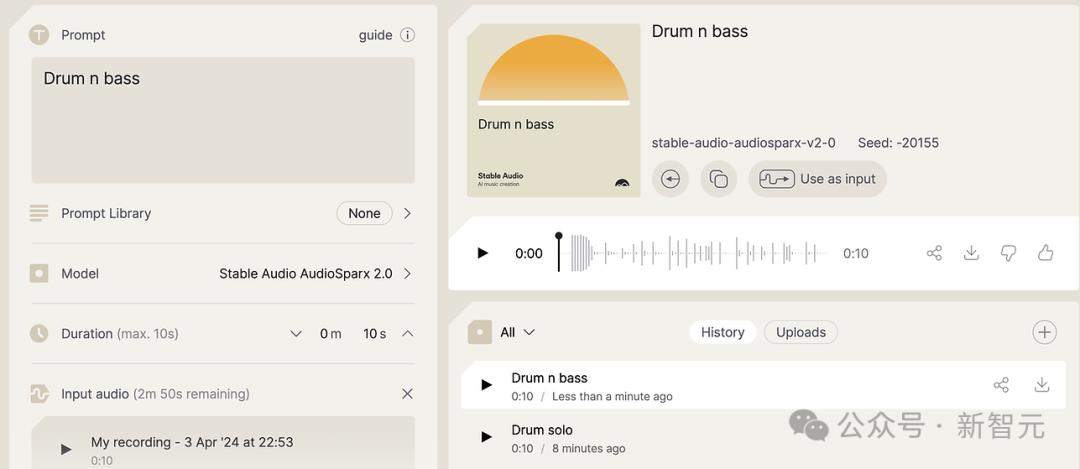
他的第一个实验,是为录制的输入捕捉一个简单的节奏,看看能否用Audio 2.0的Drum Solo功能,从提示库中获得更有趣的打击乐概念。
第一次实验的结果令人有些失望。产生的音乐的确有明确的风格和音色转移,但并没有生成他要求的「鼓的独奏」。
他尝试了第二次,提示用的是「鼓和贝斯」,这次,Audio 2.0产生了不同的鼓声,两个输出都具有修改后的捕捉音色。
从哼唱旋律到流行乐
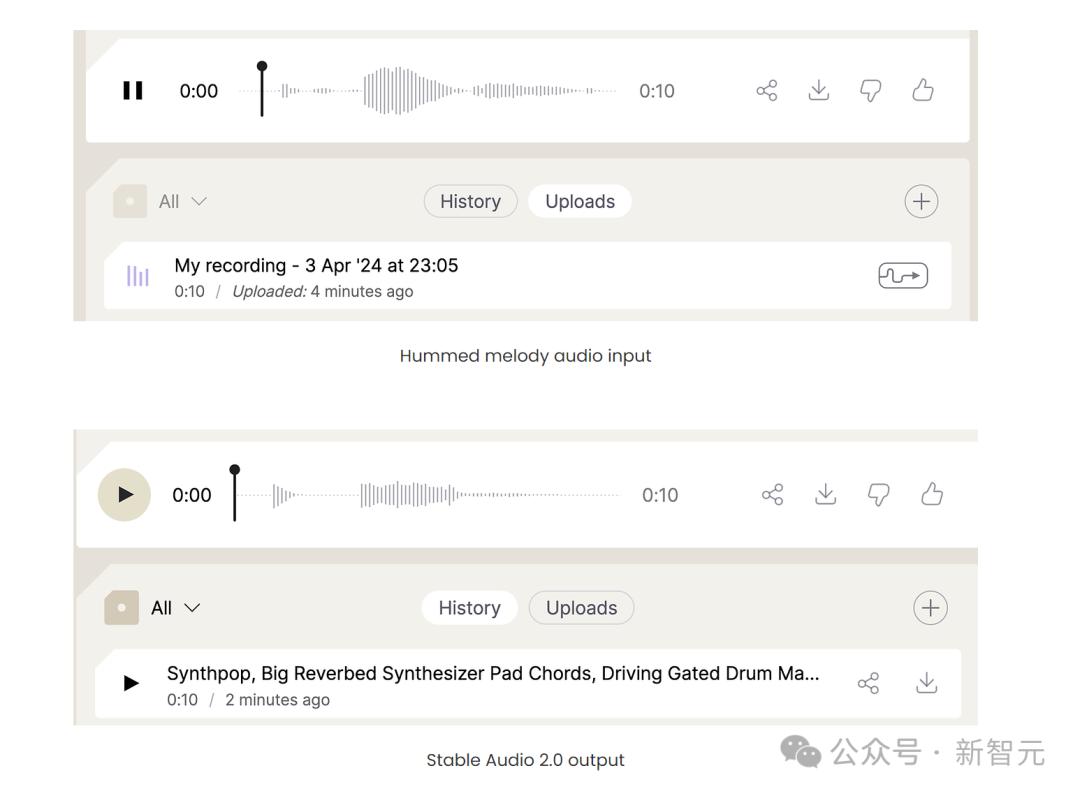
这次,小哥录下了自己哼唱的一首十秒的旋律,非常简单。
然后,他将上传的音频波形与Audio 2.0的输出进行了比较。
可以看出,输入信号中最响亮的部分跟输出中的类似波形正好对应。
但他表示,风格转移效果其实并不好。输出听起来与自己的嗡嗡声相似,但音色略有不同。
手风琴之歌到吉普赛爵士乐
总的来说,小哥的前两个实验都有点失败。
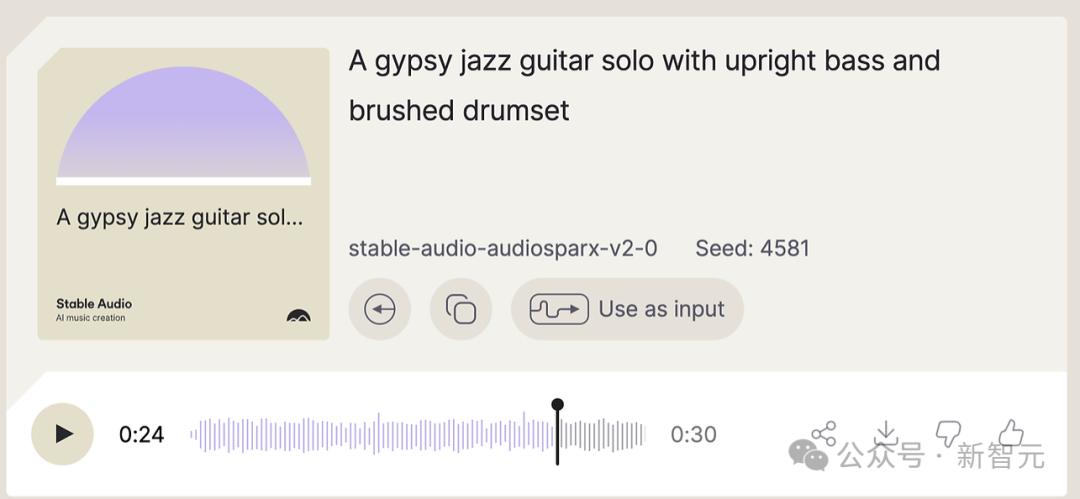
在第三次实验中,他另辟蹊径,上传了自己写的一首手风琴曲子的30秒录音。
这份录音响铃、清晰,带有和旋和旋律。
而Audio 2.0输出的结果,可以算是成功的。
不过提示要求吉普赛爵士乐,带有贝斯和鼓。但他得到的是一把原声爵士吉他,并且听起来有像是木琴的东西。没有贝斯或鼓。
这次,旋律的准确率大概在90%,但出现了原始录音中没有的一些奇怪音符。有时它会丢失主线,或早或晚地跳入旋律。
另一方面,Stable Audio确实在简单的i-iv-V7-i和弦进行上进行了创新,并进行了一些惊喜的重新和声。
所以,如果我们的目标是想出新的和弦编曲,毫无疑问,它会是一个宝藏工具。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。





