







ControlNet作者新项目,居然也搞起大模型和Agent了。
当然还是和AI绘画相关:解决大伙不会写提示词的痛点。
现在只需一句超简单的提示词说明意图,Agent就会自己开始“构图”:
a funny cartoon batman fights joker(一幅有趣的卡通蝙蝠侠与小丑战斗的图画)
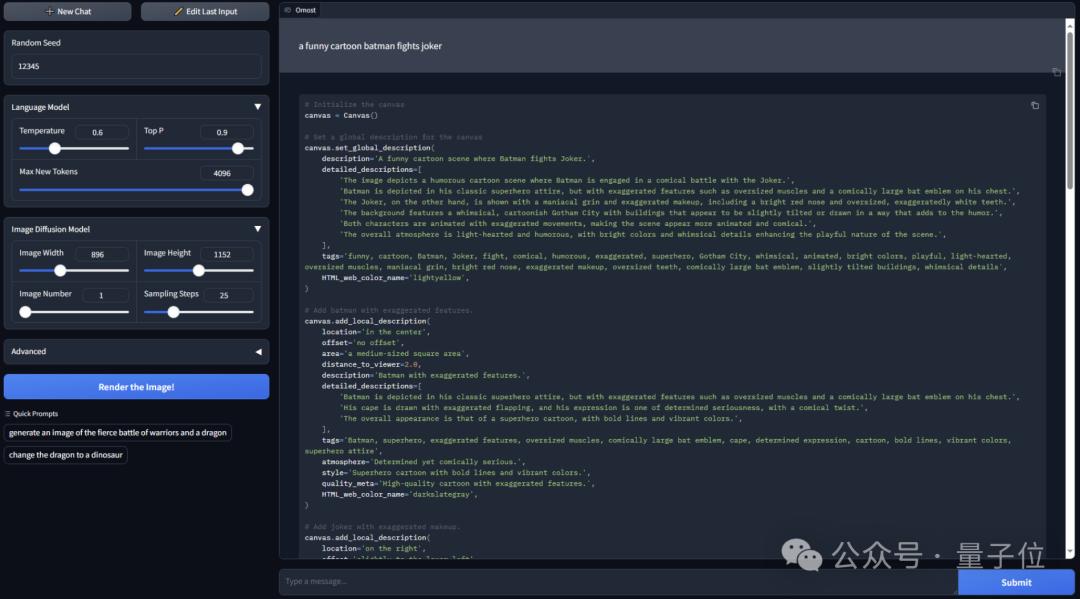
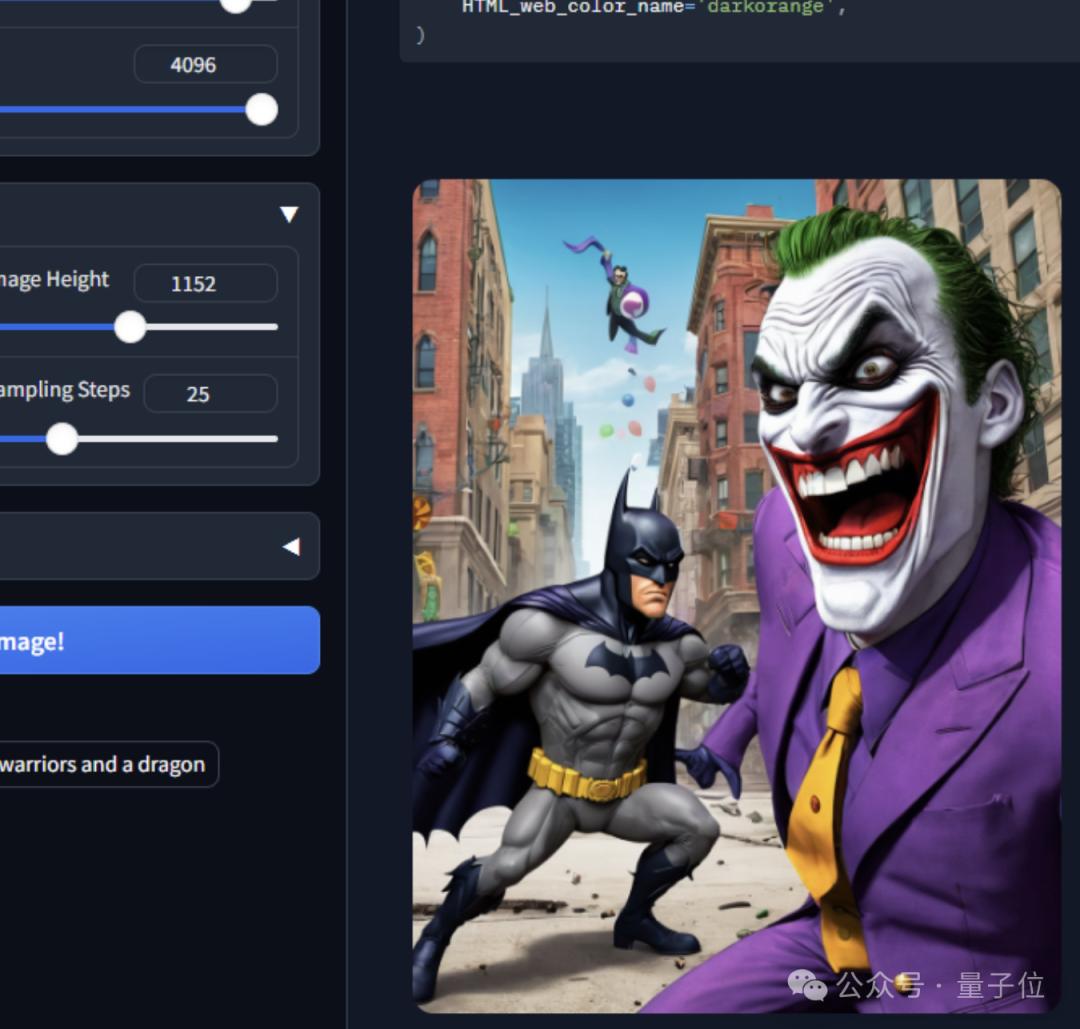
这就是ControlNet作者Lvmin Zhang的新玩具Omost。Omost这个名字有双层含义:
- 发音与英文单词almost(几乎)相似,意味着每次使用Omost后,用户所需的图像几乎就完成了;
- “O”代表“omni”(全能的),“most”表示希望最大限度地利用它。
这个新项目让网友直呼:也太强了!
放大翻译成中文来看,用户简短的提示词会被拆解扩展,从图像全局描述到局部每个元素的都会详细说明,直观地指定图像中各个元素的位置和大小。
之后,特定图像生成器根据LLM描绘的“蓝图”创建最终的图像。
而且,已经完成的图像整体布局可以保留,想修改画面中的某个元素,也只需一句提示词。
原版是这样婶儿的:
generate an image of the fierce battle of warriors and the dragon(生成勇士与龙的激烈战斗的图像)
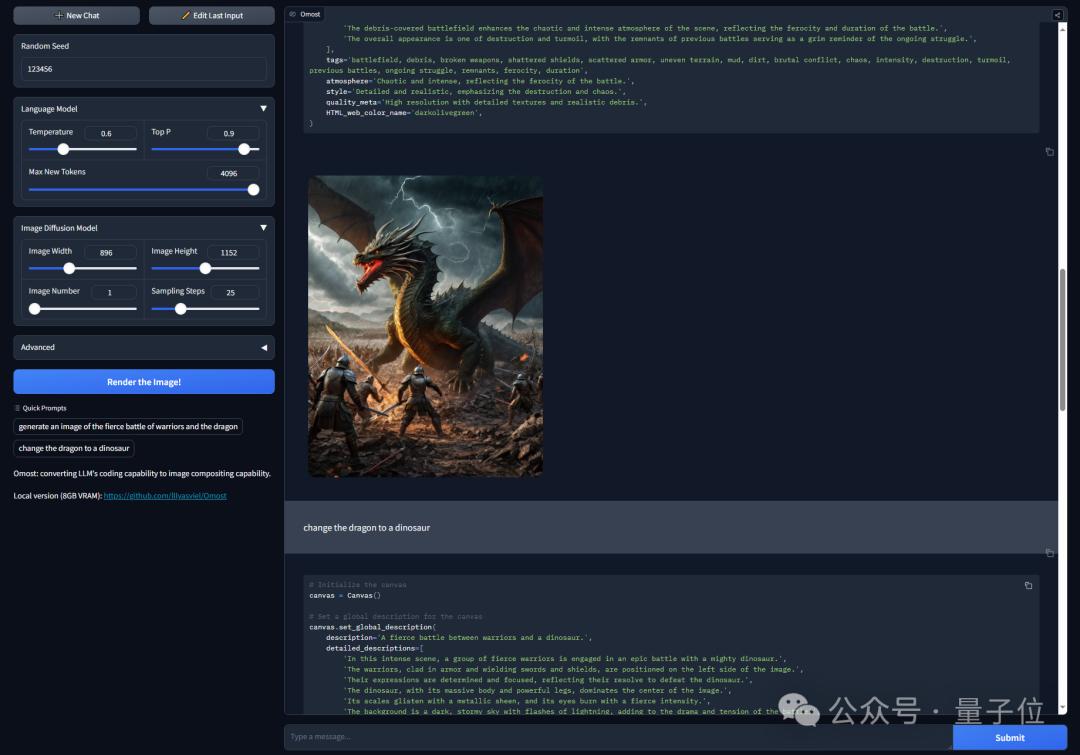
然后把龙变成恐龙:
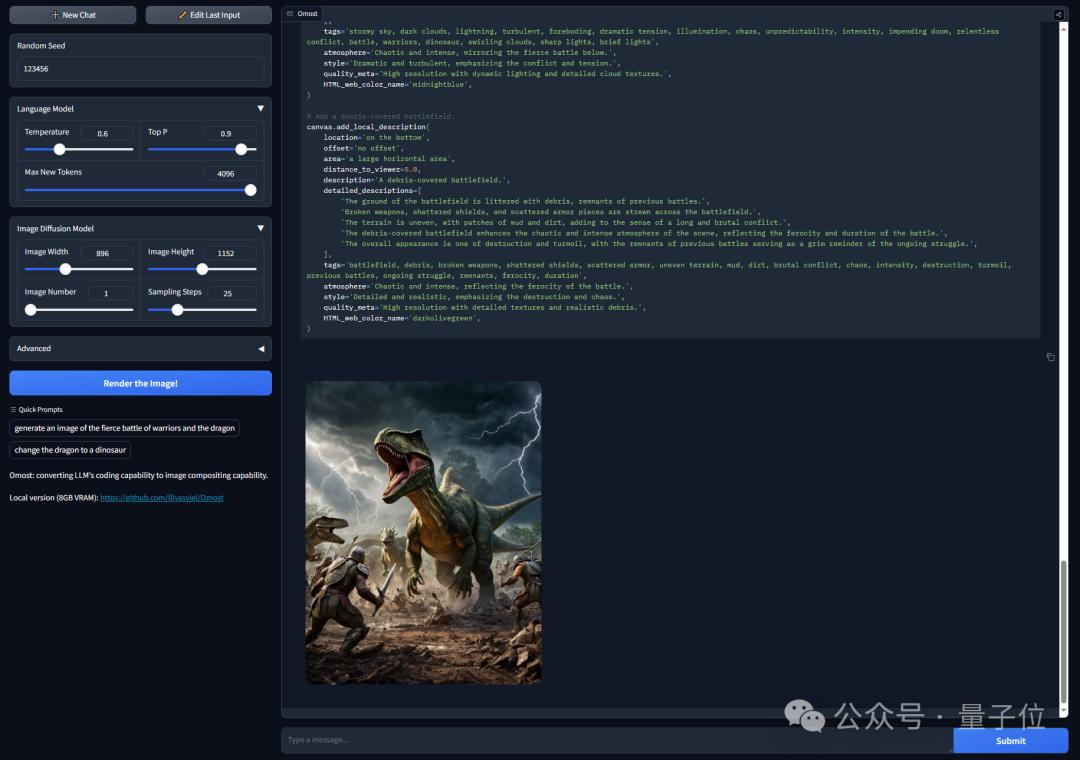

目前,Omost用来生成代码的LLM有基于Llama3和Phi3变体的三种模型,Lvmin Zhang还放出了Demo大伙儿可以试玩。
网友们第一时间也纷纷上手尝试:

不禁感慨Lvmin Zhang的项目都很鹅妹子嘤:

729个框,设定图像所有元素的位置
Omost目前提供基于Llama3和Phi3变体的三种LLM。
下面扒开Omost看看里面有什么。
首先,所有的Omost LLM都经过训练,可以提供严格定义的子提示,大伙儿可以利用其来设计无损文本编码方法。
“子提示”(sub-prompt)指的是如果一个提示少于75个token,并且能够独立描述一个事物,不依赖于其他提示,就是“子提示”。
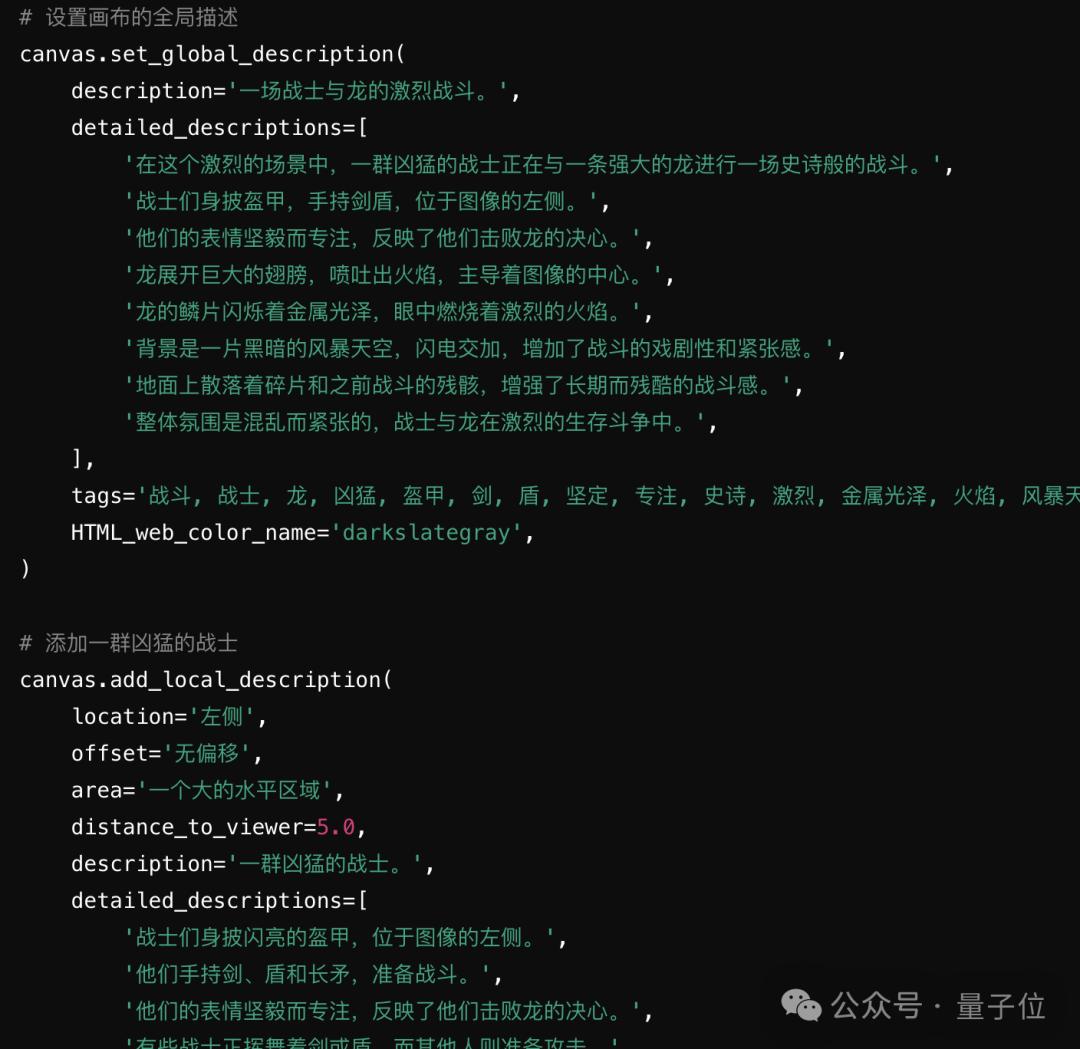
Omost通过预定义的位置、偏移量和区域这三大参数来简化图像元素的描述。
首先将图像划分为3*3=9个位置:
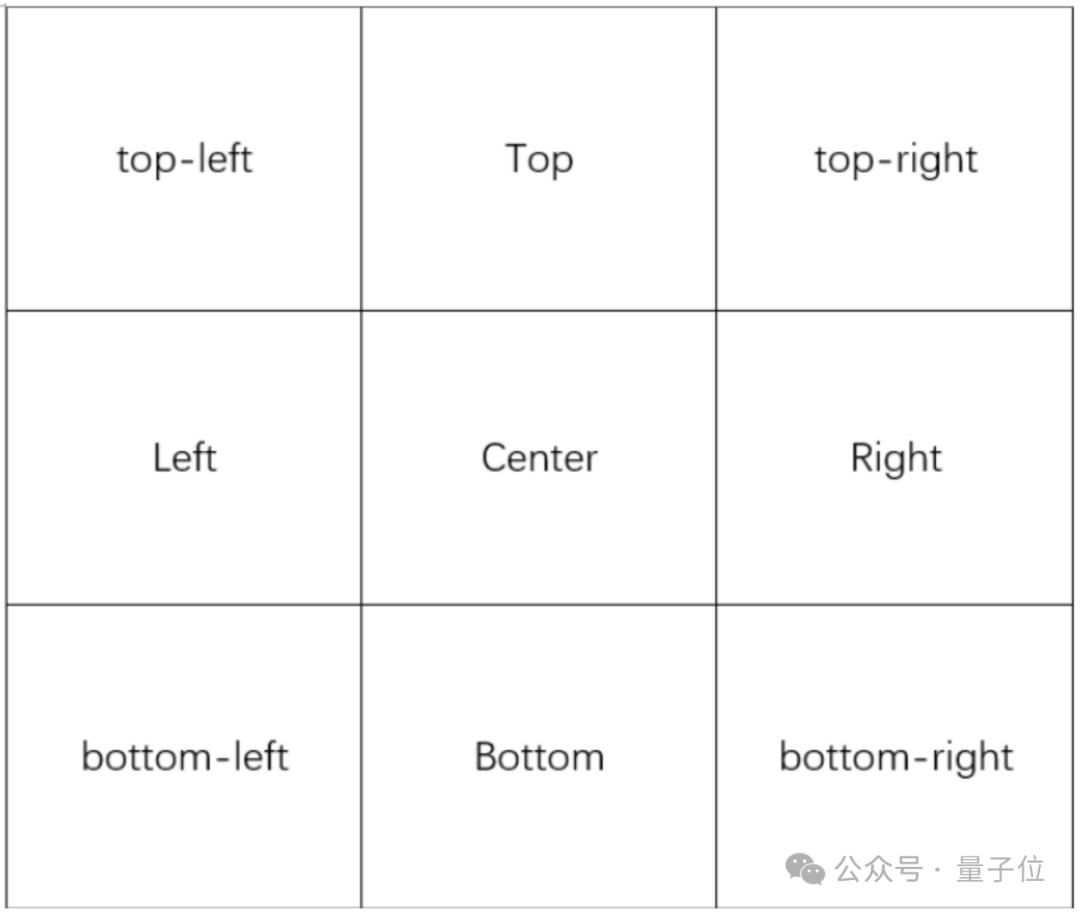
然后进一步将每个位置划分为33个偏移量,得到99=81个位置:
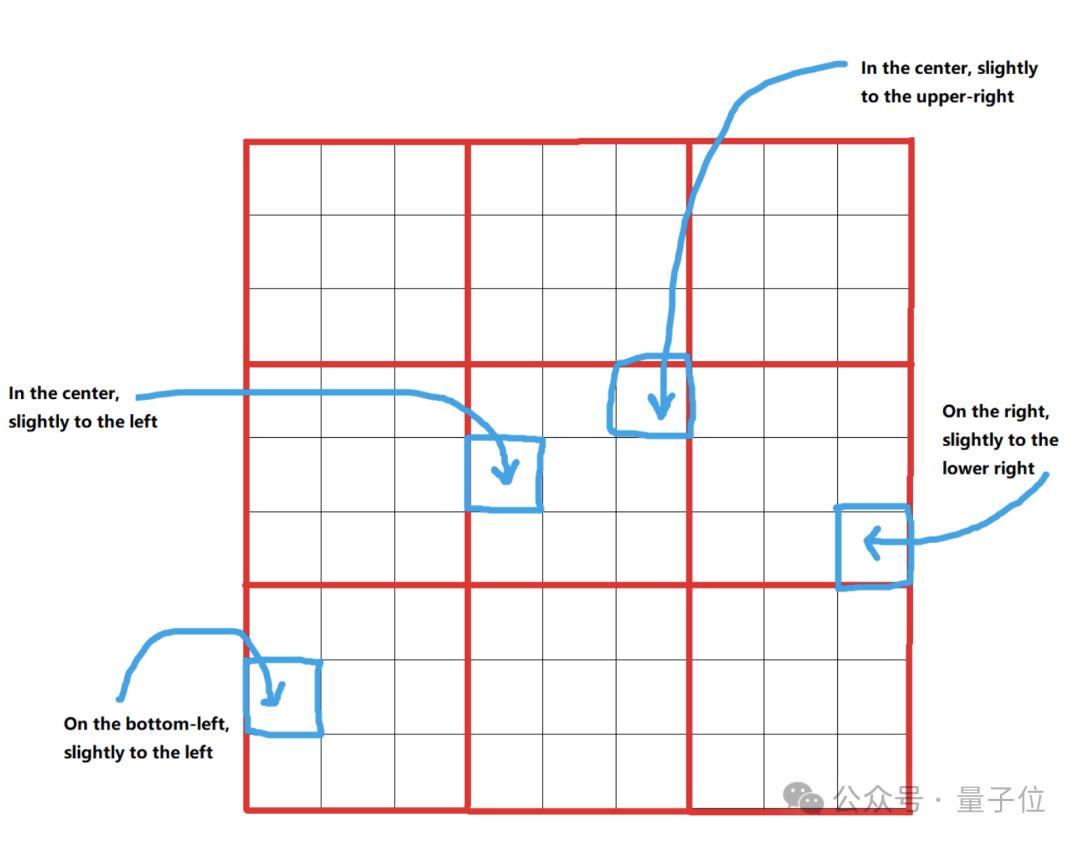
以这些位置为中心,进一步定义了 9 种类型的边界框:

如此一来就涵盖了999=729个不同的边界框,几乎涵盖了图像中元素的所有常见可能位置。
接下来,distance_to_viewer和HTML_web_color_name两大参数调整视觉表现。
组合distance_to_viewer和HTML_web_color_name可以绘制出非常粗糙的构图。
例如,如果LLM效果良好,“在暗室的木桌上的红瓶子前面有一个绿色瓶子”应该可以计算出如下图像:

此外,ControlNet作者Lvmin Zhang还提供了一个基于注意力操纵的Omost LLM的baseline渲染器。并总结了目前要实现区域引导的扩散系统的一些选择。
基于注意力分数操作,他编写了一个baseline公式,并认为这种无参数公式是一个非常标准的baseline实现,几乎会引入zero style偏移或质量下降。将来,他们可能会考虑为Omost训练一些参数化方法。
具体来说,现在考虑一个只有2*2=4像素的极简化图像:
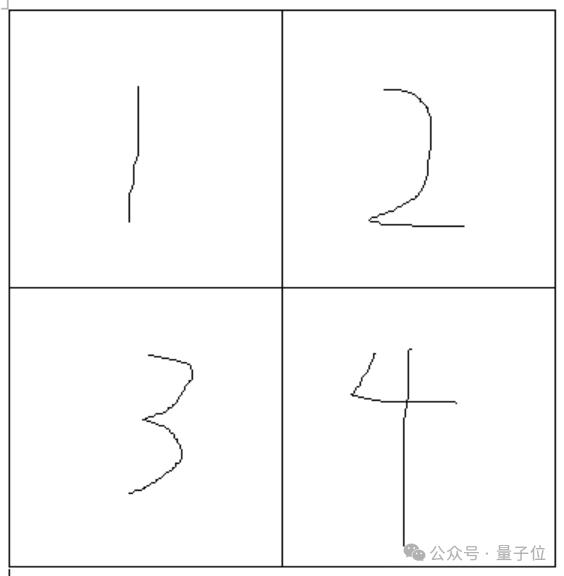
有三个提示“两只猫”、“一只黑猫”、“一只白猫”,有它们的掩码:

然后就可以画出这个注意力分数表:
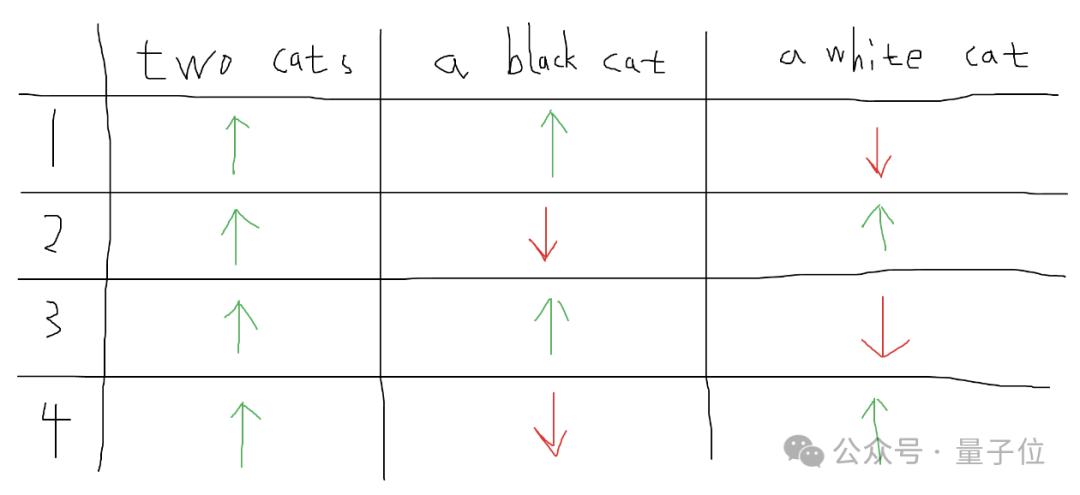
简而言之,就是通过调整注意力分数来控制模型在不同区域的关注度,来实现更精细的图像生成。
此外,Lvmin Zhang还发现了另一种可以提高提示理解的技巧,并称其为提示前缀树(Prompt Prefix Tree)。
因为现在所有的提示都是可以任意合并的子提示(所有子提示严格少于75个token,通常少于40个标记,描述独立的概念,并且可以任意合并为clip编码的常规提示),找到一种更好的方法来合并这些子提示可能会改进结果和提示描述。
例如,下面是一个全局/局部整体/详细描述的树结构:
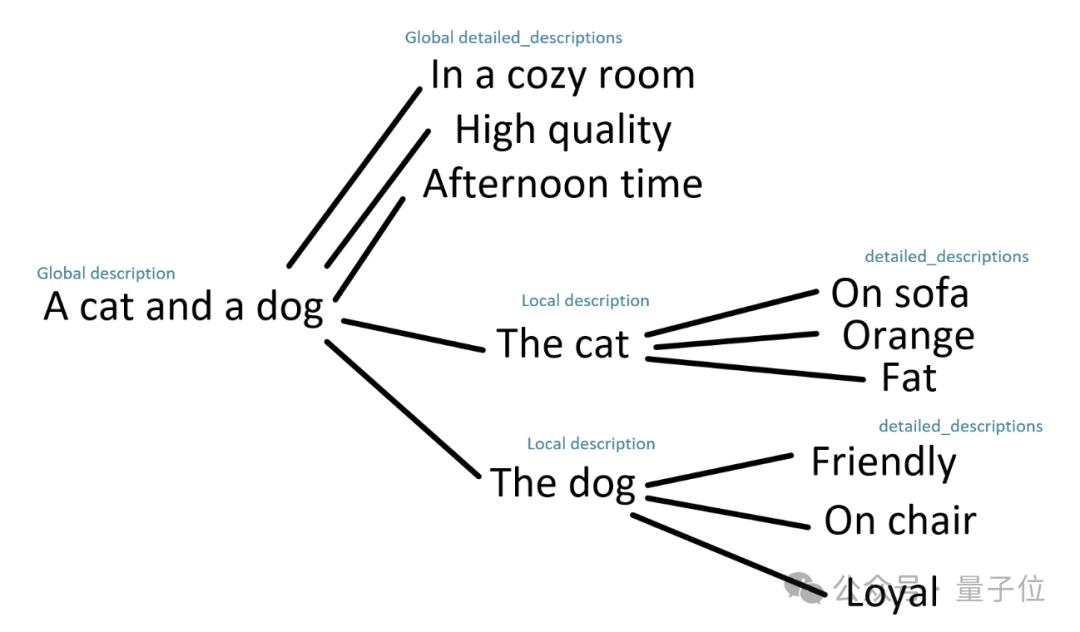
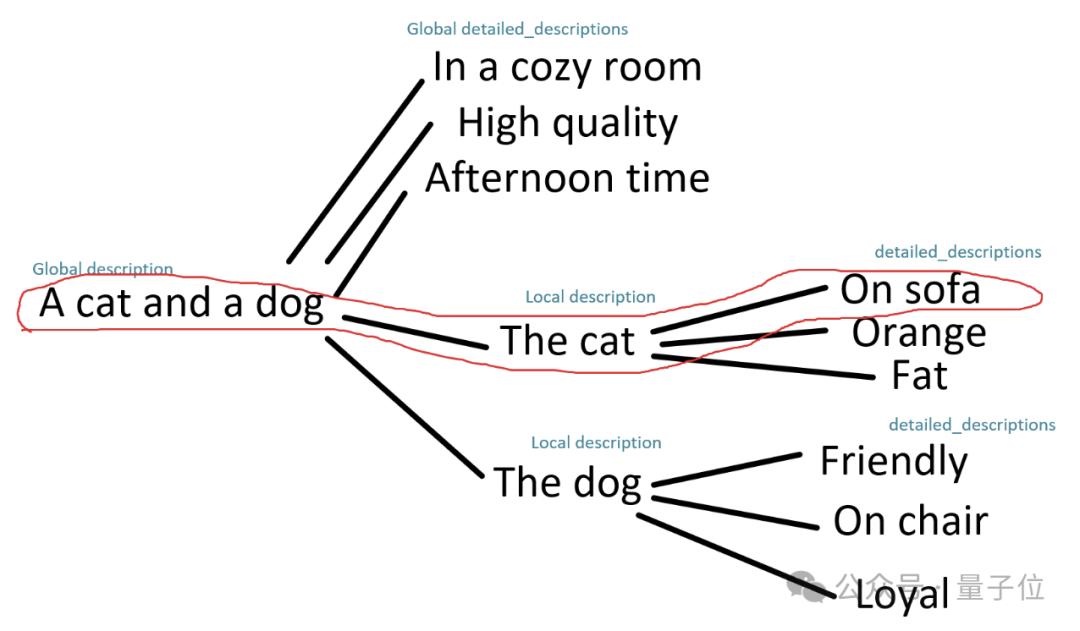
由于所有子提示都可以任意合并,因此可以将此树形图中的路径用作提示。
例如,下面的路径将给出提示“一只猫和一只狗。沙发上的猫”。
感兴趣的家银亲自上手玩玩吧~
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。




