







距离普通人凭想法就能做出游戏的时代,又近了一步。
AI游戏生成天花板今年以来不断突破,就在昨天,国产游戏AI团队也加入卷出了新高度。
巨人网络发布了“千影 QianYing”有声游戏生成大模型,其中包括游戏视频生成大模型YingGame、视频配音大模型YingSound。
先来感受一段1分26秒的生成样片:
用一段文字、一张图,就能生成模拟开放世界游戏的视频,并且有声、可交互,可操控角色的多种动作。
面向开放世界游戏,无需游戏引擎
概括来说,YingGame 是一个面向开放世界游戏的视频生成大模型,研究团队来自巨人网络AI Lab、清华大学SATLab,首次实现角色多样动作的交互控制、自定义游戏角色,同时具备更好的游戏物理仿真特性。
精确的物理规律仿真
从生成的视频中看,无论是汽车碰撞、火焰燃烧这类大场面,还是水中慢走、障碍物自动绕行这种人物行进,都表现出了出色的遵循物理规律能力。

多样动作控制
交互对游戏至关重要,YingGame能够理解用户的输入交互,包括文本、图像或鼠标、键盘按键等操作信号,从而让用户能够操控游戏角色的多样动作。
视频中展示了角色在开枪、变身、施法、使用道具、攀爬、匍匐、跑跳等肢体动作的交互,相比同类模型更加丰富、丝滑。

角色个性化与精细主体控制
YingGame还支持输入一张角色图片,实现角色自定义生成,同时对角色主体实现精细化控制,从过去的AI捏脸跨越到现在的AI捏人。

第一人称视角
此外,还看到模型生成的第一人称视角的游戏画面,不得不说,这个视角有很足的游戏沉浸感。

怎么实现的?
从技术上看,YingGame 通过融合跨模态特征、细粒度角色表征、运动增强与多阶段训练策略,以及所构建的高效、高质量游戏视频训练数据生产管线,使得生成内容具备可交互能力的多样动作控制、角色自定义与精细主体控制、复杂运动与动作连续性等特性。
在交互性实现上,YingGame 结合了多个Interactive Network模块:理解用户输入的多模态交互方式,实现多样动作控制的多模态交互网络 — MMIN (Multi-Modal Interactive Network);实现复杂与连续角色动作生成的动作网络 — IMN (Interactive Motion Network);自定义角色生成与提高角色生成质量的角色网络 — ICN (Interactive Character Network)。
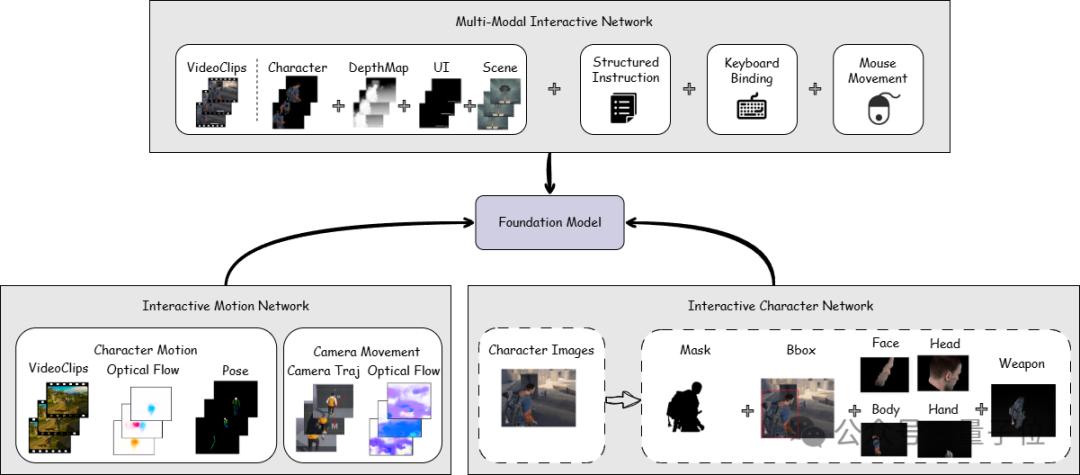
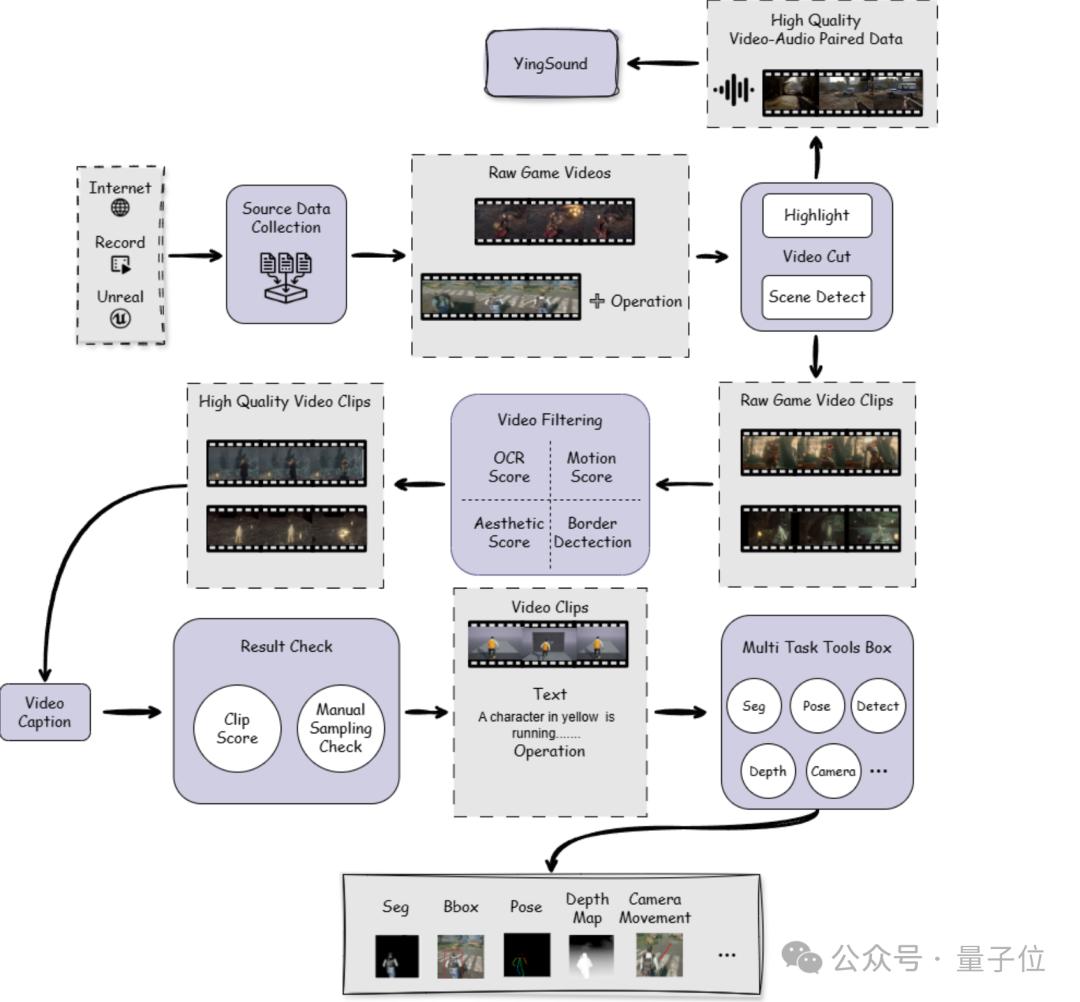
此外,为实现高质量训练数据构建,巨人AI团队设计了一条高效的游戏视频数据处理管线:
基于场景与高光产出高质量视频片段,其中对高光视频片段进行音频信息提取,作为V2A训练集;
基于运动得分、美学评分等进行视频过滤;
vLLM-based video caption流程,并对结果进行clip score文本视频对齐评分过滤;
多任务数据处理,如分割、主体检测、姿势估计、深度估计、相机运动估计等。
让AI游戏进入有声时代
除了YingGame之外,巨人还发布了针对视频配音场景的多模态音效生成大模型 YingSound。
这是在此之前AI游戏生成领域没有实现的,而“声音”是游戏的基本要素。
YingSound 由巨人网络AI Lab、西工大ASLP Lab和浙江大学等联合研发,它最重要的技能是:给无声视频配音效,实现音画同步。
YingSound有超强的时间对齐和视频语义理解能力,支持多种类型的高精细度音效生成,并且具备多样化应用场景泛化能力,包括游戏视频、动漫视频、真实世界视频、AI生成视频等。
理解各种视频画面能力一绝
来一段游戏的配音示例,通过演示视频可以清晰看到,这个模型能够精确地生成与场景高度匹配的音效,包括开镜、炮轰、射击等声音,完美还原坦克进攻与士兵防守射击的声音,创造了沉浸式的游戏体验。
在动漫场景中,模型展示了对复杂剧情的理解能力。例如,在一段鸟儿互相扔蛋的动画中,模型生成了从惊讶到扔蛋、蛋飞行轨迹、接住蛋等一系列卡点且高度符合视频内容的音效。
再来看看以下小球快速移动的画面,模型生成的声音能够精准匹配画面的动态变化,并针对小球不同状态生成相应的场景音效,充分展现了其对动画内容的深度理解。
在真实世界场景中,通过一段激烈的乒乓球对战视频,模型能够精准地生成每次击球所产生的音效,甚至还生成了球员跑动时鞋底与地面摩擦的声音,这充分展现 YingSound 对视频整体语义的深刻理解和出色的音效生成能力。
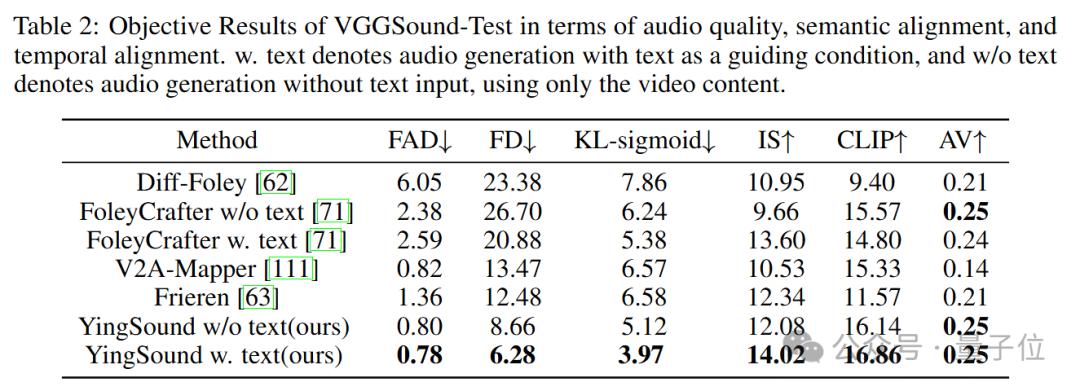
测评结果领先
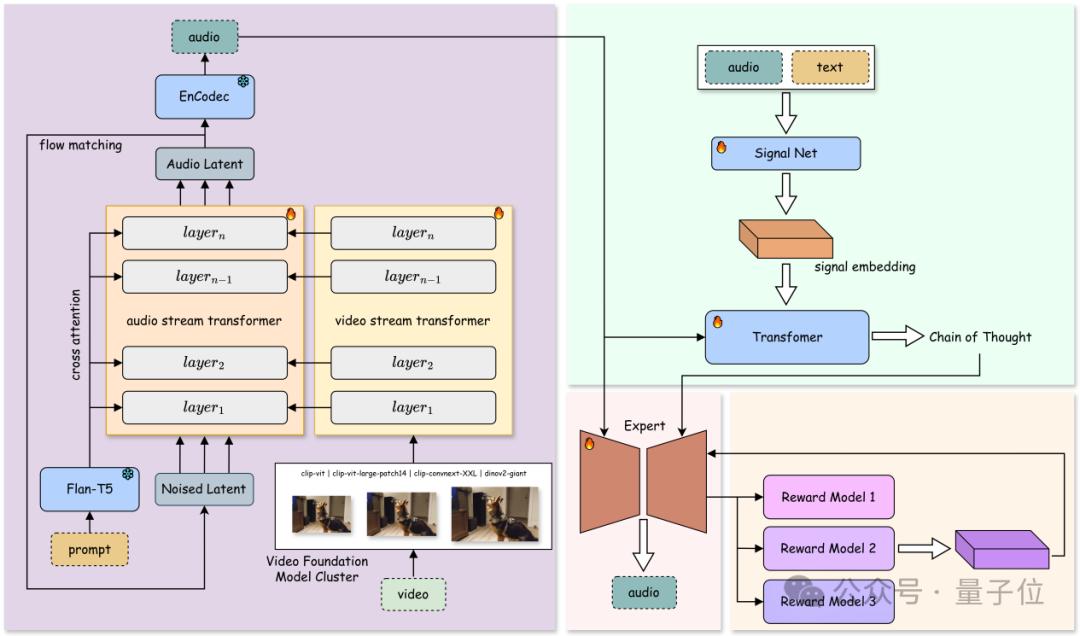
研究团队公开了 YingSound 的两个核心模块:基于 DiT 的 Flow-Matching 构建的音效生成模块,以及多模态思维链(Multi-modal CoT)控制模块,为音效生成提供精准支持。
在音效生成模块中,团队基于 DiT 的 Flow-Matching 框架,提出了创新的音频-视觉融合结构(Audio-Vision Aggregator, AVA)。该模块通过动态融合高分辨率视觉与音频特征,确保跨模态对齐效果。通过多阶段训练策略,逐步从 T2A 过渡到 V2A,并采用不同数据配比训练,使模型具备从文本、视频或二者结合生成高质量音效的能力。
同时,团队设计了多模态视频-音频链式思维结构(Multi-modal CoT),结合强化学习实现对少样本情况下音效生成的精细控制,可广泛适用于短视频、动漫及游戏等配音场景。
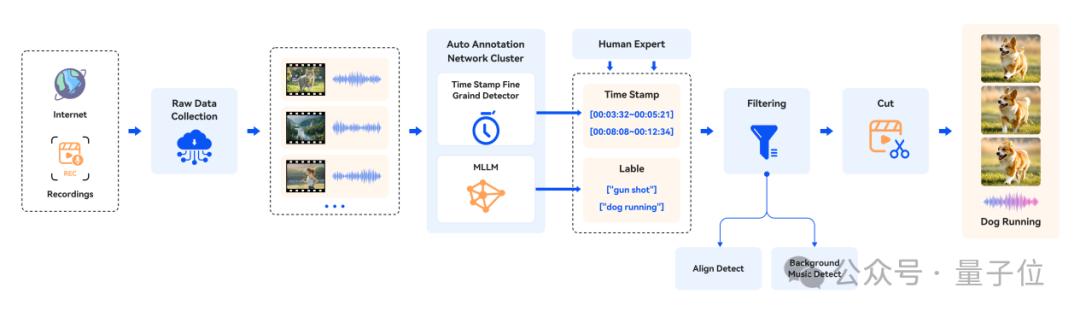
团队精心构建了符合行业标准的V2A(video-to-audio)数据集,覆盖了电影、游戏、广告等多场景、多时长的音视频内容。为确保数据质量,研究团队还设计了一套完善的数据处理流程,涵盖数据收集、标注、过滤和剪辑。针对不同视频类型的复杂性与差异性,团队基于多模态大语言模型(MLLMs)及人工标注,完成时间戳和声音事件的高质量标注。同时,通过严格筛选,过滤掉背景音乐干扰及音视频不同步的内容,最终生成符合行业标准要求的训练数据,为后续研究与开发提供了坚实基础。
通过客观指标测评可以看出,YingSound 大模型在整体效果、时间对齐和视频语义理解等客观测评上均达到业界领先水平。
长期来看,视频生成技术因其展现出的取代游戏引擎的潜力,势必会对游戏行业带来颠覆式创新。
通过文字描述就能创作一个游戏,不再是异想天开。这个领域的发展速度之快超乎想象,AI将带来游戏创作平权,未来游戏创作的唯一限制可能只是创作者们的想象力。
今年年初,史玉柱谈到巨人网络在探索打造一个AI游戏孵化平台,降低做游戏的门槛,让普通人也能做游戏。这不,年底就交了第一份“作业”,期待他们在AI游戏赛道的下一步规划。
更多细节,可戳下方链接查看完整技术报告。https://giantailab.github.io/yinggame/https://giantailab.github.io/yingsound/
*本文系量子位获授权刊载,观点仅为作者所有。
本文来自微信公众号“量子位”,作者:允中
您可能关注: AI游戏
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。



