








随着深度学习技术的不断进步和模型规模的扩大,“智能涌现”为大模型赋予了触类旁通的能力,也带来了日益凸显的幻觉问题。
首先,我们要思考一个问题,什么是大模型的“幻觉”?
所谓大模型幻觉,主要指的是模型输出了和现实世界不一致的内容,例如捏造事实、分不清虚构与现实、相信谣言和传说等,也就是我们常说的“一本正经的胡说八道”。在实际应用场景中,幻觉问题不仅影响了模型的准确性和稳定性,还制约了大模型在真实场景中的广泛应用的可靠性。因此,如何解决大模型幻觉一直是大模型走向全面产业应用的关键课题。
近日,复旦大学联合上海人工智能实验室构建了大模型幻觉评估数据集HalluQA,数据集涵盖了30个领域,数据集关注大模型在实际应用中可能面临的问题。其中诱导(Misleading)和知识(Knowledge)两部分问题着眼于模型的模仿性谎言(Imitative Falsehoods)和事实性错误(Factual Errors)。
在HalluQA幻觉评测数据集中,复旦大学团队用“无幻觉率”这一指标来评估模型的能力。无幻觉率的高低(越高越好)不仅直接反映了展示了不同模型在解决幻觉问题上的优劣,与事实准确性密切相关,也为模型在实际应用中的可行性提供指导。
最近评测,谁解决幻觉能力最好?
HalluQA评测集的出现,为行业提供了一个更加专业的方法,能够看到在攻克大模型技术的演进过程中,哪些是真正的“有备而来”,哪些是死读书的“做题家”,还有哪些是“裸泳者”。
值得注意的是,HalluQA团队还在报告中对业界主流的24个大模型进行了大模型幻觉评估。结果显示,仅有6个大模型取得了高于50%的非幻觉率,仅有所有参测模型的1/4。其中,百度文心一言(Baidu ERNIE-Bot)在评测中以69.33%的无幻觉率成为榜单中的第一名。GPT-4的整体无幻觉率为53.11%,排名第六。
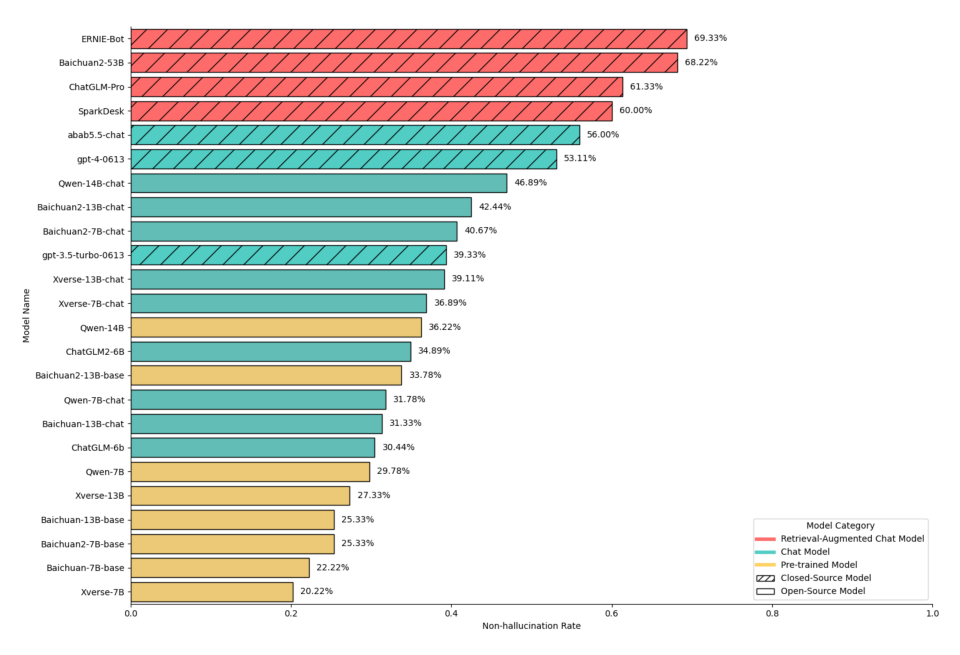 中文大模型幻觉评测数据集HalluQA对24个主流大模型进行评测
中文大模型幻觉评测数据集HalluQA对24个主流大模型进行评测大模型幻觉问题的产生主要归因于模型复杂性和数据质量。随着模型规模的不断扩大,模型的复杂度也相应增加,容易导致过拟合现象,使得模型过于依赖于训练数据中的细节和噪声,难以泛化到新的数据上,进而产生幻觉。另外,数据质量对于大模型性能的影响也不可忽视。如果训练数据存在偏见、噪声或不足以覆盖真实场景的多样性,模型就难以学习到准确的数据分布,从而出现幻觉问题。

目前,行业主要解决大模型幻觉的方式,除了通过预训练、微调等模式,夯实的大模型的理解与泛化能力之外,主要的方法一个是利用对齐技术可以显著减少回答误导性问题时出现的幻觉;另外一个则是通过对大模型引入检索增强,可以大幅提高模型在长尾知识类问题上的非幻觉率。
模型具体需要怎么做来降低幻觉问题呢?从复旦大学发表的论文来看,首先,模型要拥有强大的基础能力。比如,文心一言所基于的是百度的文心大模型4.0版本,已知的信息是它基于数万亿数据和数千亿知识进行预训练,提升模型的泛化能力和事实准确性,通过有监督精调、人类反馈强化学习等手段,保证模型更好地与人类的判断和选择对齐,来降低模型产生幻觉的风险。另外检索增强技术特点也为解决幻觉问题提供了重要支持。比如文心一言基于语义理解与匹配的新一代搜索架构来提高输出内容的准确性和时效性,进一步降低幻觉问题的出现。
谁能更好地解决大模型幻觉问题,谁更易被企业应用
大模型幻觉问题的产生根植于语言模型的复杂性。这些模型通过训练大量的数据和知识来生成文本,但在实际应用中,如果大模型会笃定地说出错误的答案,可能会产生不准确或有误导性的结果,这对于客户服务、金融服务、法律决策和医疗诊断等多个对于专业度与准确率要求极高的领域,会导致大模型难以胜任实际场景中的任务。
可以说,大模型产业落地,已经苦“幻觉”久矣。哪家大模型能够率先降低大模型幻觉的影响,就能够在如今“百模大战”的角力中取得先机。
更低的幻觉正在成为了更多企业选择大模型的重要原因。
大模型之家相信,随着大模型幻觉评测标准的出台,将会为大模型能力发展打开全新的维度,让更加可信、可靠的人工智能得以向产业普及。我们也看到越来越多在解决幻觉问题上的技术创新,推动解决大模型幻觉问题。在技术与标准并行发展的格局之下,大模型将在各个领域发挥出更大的价值,为人类生活带来更多便利与惊喜。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。





