








本文内容从技术角度介绍推荐系统、AI 大模型前沿技术。整理一些大模型和推荐系统相关的交集。同时,我从产品、技术发展趋势,大胆预测 AI 大模型对未来推荐系统的影响。本文适合关注 AI、推荐系统相关领域的朋友。考虑到 AI、LLM、推荐算法本身晦涩难懂,很多专门学科知识,我尽量用易懂的原理图解释,相关部分附上更深度的技术介绍链接。本文希望从产品、技术、商业多维度分析推荐系统未来的趋势和 AI 大模型带来的革新价值。
一、介绍
推荐系统广泛用于众多领域,只要存在“消费商品”的互联网产品,都需要推荐系统。
无处不在的推荐系统
以下是一些知名的提供 AI 推荐系统产品和服务的公司:
- Netflix - 利用协同过滤算法为用户推荐电影和电视节目
- Amazon - 使用基于项目和基于内容的推荐算法推荐产品
- YouTube - 使用深度神经网络推荐个性化视频内容
- Spotify - 基于音乐元数据和用户行为数据推荐音乐
- Facebook - 利用深度学习模型推荐好友、页面和新闻源
- Google - 在搜索、Gmail、YouTube等产品中使用推荐系统
- Pinterest - 使用计算机视觉和深度学习推荐相关图像和想法
- Alibaba - 在电商平台上为用户推荐商品
- Tencent - 在微信、QQ等应用中使用推荐算法
- Twitter - 推荐相关主题、用户和趋势
上面是 AI 帮我们回答的
- 具体来说推荐系统的应用领域主要有如下几类:
- 电商网站:购物,购书等,如淘宝,京东,亚马逊等
- 视频内容:Netflix,优酷,抖音,快手,爱奇艺等
- 音乐:网易云音乐,酷狗音乐等
- 资讯类:今日头条,微信订阅推荐等
- 生活服务类:美团,携程,脉脉等
- 交友类:探探,珍爱网等
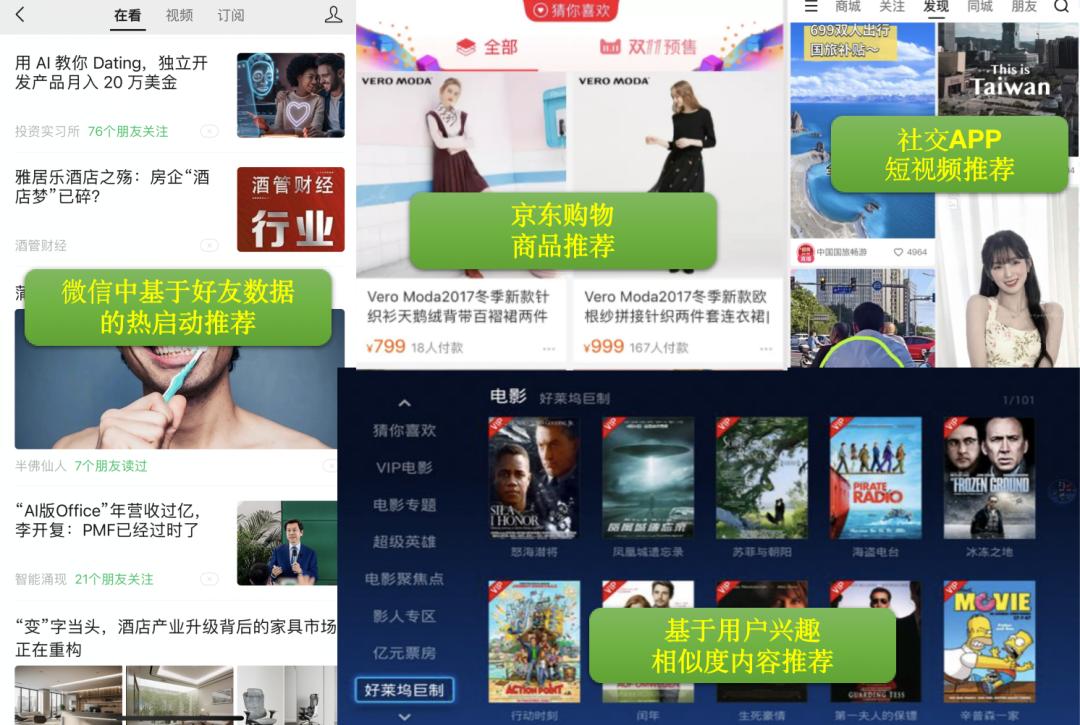
推荐系统的价值
推荐服务用途非常广泛,粗略汇总有五个维度的商业价值:
- 广告变现:提升广告的曝光与用户转化率;
- 电商变现:主要通过给用户和产品"打标签",推荐商品达到刺激复购率和电商营销。比如各大电商平台看到的"猜你喜欢","更多推荐","热门商品"等推荐功能;
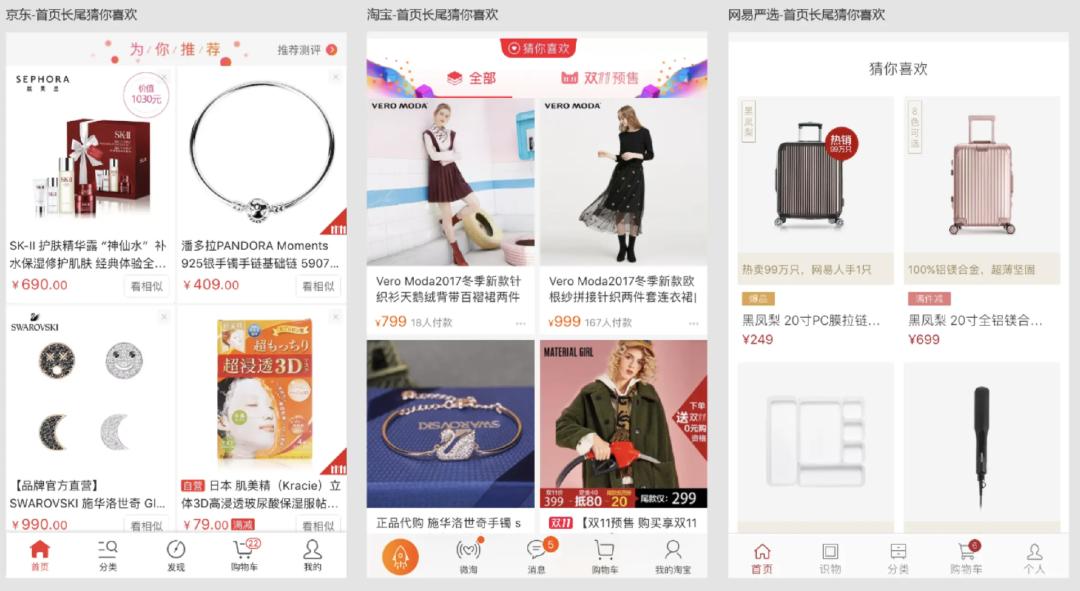
Taobao、京东、网易严选中'猜你喜欢'功能
- 增值服务变现:提升会员的转化与会员留存;
- 用户增长:提升用户留存、活跃、停留时长,常见抖音内容类推荐的 APP;
- 个性化推荐替代采用人工编排:节省人力成本,提升内容分发效率。
推荐系统的实现架构和核心模块
推荐系统根据不同场景,不同数据体量,系统设计差异跨度非常大。常见来说,有这么几个部分:
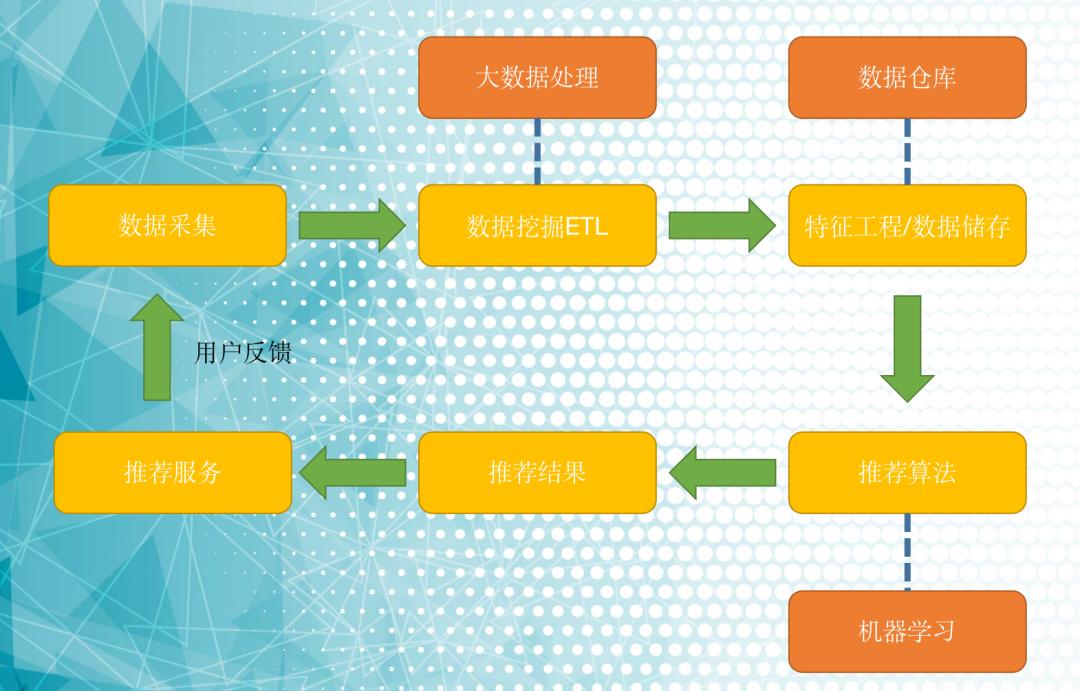
数据采集模块
推荐系统展示结果给用户后,通过在线系统收集用户反馈数据,包括用户行为数据,用户相关数据及推荐“标的物”相关数据。
数据挖掘 ETL 模块
将非结构化数据提取成结构化数据储存到数据仓库中。当数据量非常大,一般采用 HDFS、Hive、HBase 等大数据分布式存储系统来存储数据。
特征工程模块
推荐系统采用各种机器学习算法来学习用户偏好,并基于用户偏好来为用户推荐“标的物”, 而这些推荐算法用于训练的数据是可以“被数学所描述”,就是机器学习里面的 Embedding 过程Embedding用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。
浅谈 IDs Embedding
Word Embedding
近年来词嵌入方法(Word Embedding)被普遍用于 NLP 领域,它将过去机器学习中 One-Hot 表示的单词嵌入(Embed)至低维,以一个带有语义信息的低维稠密向量来表示:
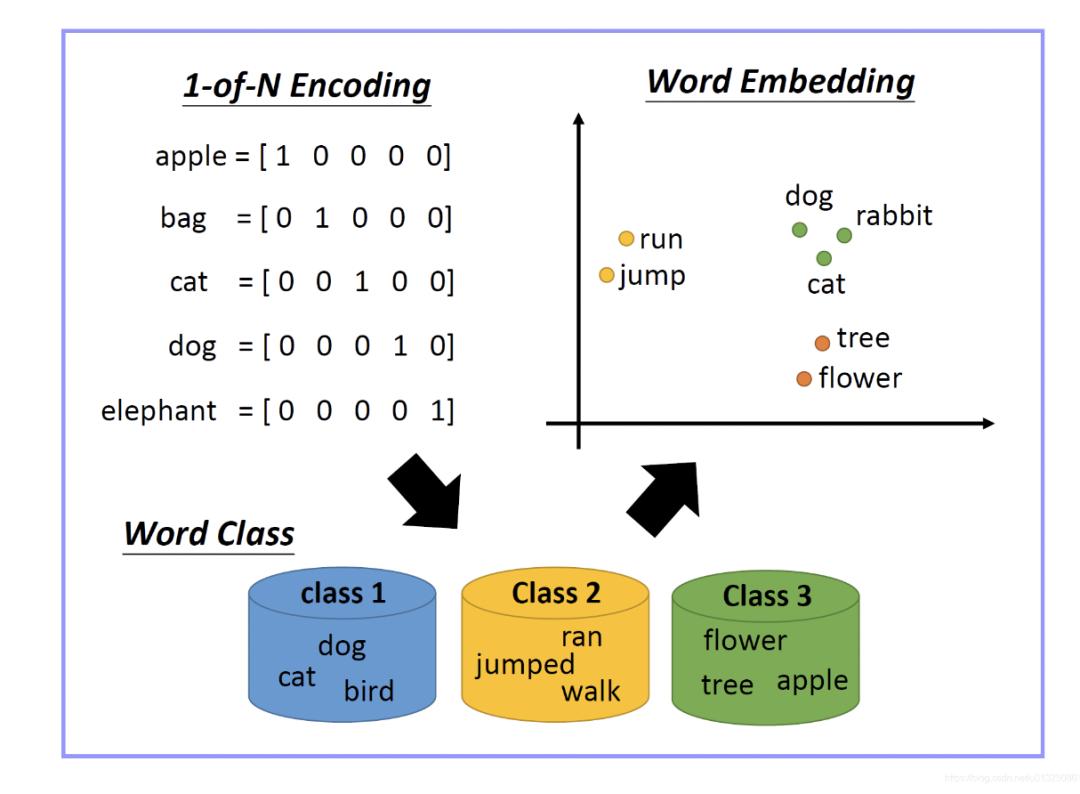
One-Hot 和 Word Embedding 原理和对比
在数据挖掘问题中普遍存在各种各样的离散特征(通常称为 ID 类特征),传统的做法是使用 One-Hot 编码进行表征。它虽然简单,但是当离散特征种类过多时,很容易造成维数灾难 (curse of dimentionality) 。One-Hot 编码无法看出特征的内在含义,无法了解 ID 特征之间的相互联系。
以电商领域为例,包括商品信息、店铺信息、品类信息和评论信息等等,其中存在大量 ID 类特征,比如 user ID, item ID, product ID, store ID, brand ID 和 category ID,而这些 ID 特征彼此间有复杂的层级关系。
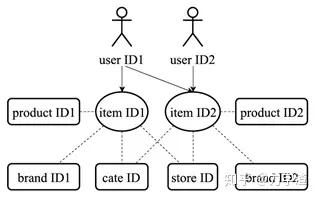
IDs embedding 来建模物品的协同过滤算法已经成为推荐系统最主流的范式,十多年来一直是推荐系统主流方案。学术界把 ID embedding 对物品进行建模简称为 IDRec。
推荐算法模块
该模块的核心是根据具体业务场景,和已有的数据设计一套大规模数据的 (分布式) 机器学习算法,期望可以准确预测用户的兴趣偏好。这里一般涉及到模型训练、预测两个核心操作。机器学习的流程中,一般往往不断的训练,预测,损失函数调参的过程损失函数(Loss Function)它用于量化模型的预测结果与实际结果之间的差异,作为训练过程中优化算法的目标。在机器学习中,损失函数用于各种不同类型的算法,包括线性回归、逻辑回归、支持向量机等。它们帮助算法通过最小化损失函数来调整参数,以此改进模型的预测性能。
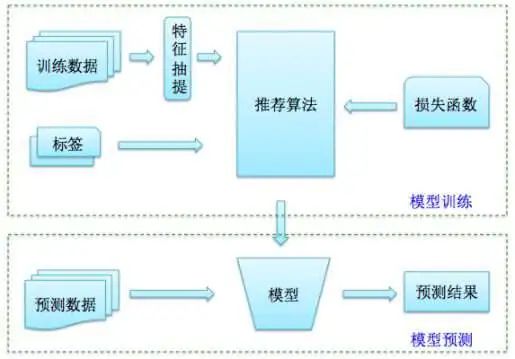
推荐结果:打分排序、排序阶段的召回、粗排、精排等过程。
一个完整推荐系统生命周期
美团团购猜你喜欢的历史:
- 0-1 关系型数据库+搜索引擎
不是每家公司早期有足够研发成本和海量数据,支撑分布式机器学习的投入数据采集和数据挖掘采用关系型数据库,特征工程和推荐算法借助搜索引擎
https://mp.weixin.qq.com/s/fdxoRJnajFE1UTZewofFQg
- 10-100 机器学习阶段
机器学习主要使用 TensorFlow DRL 框架,Embedding 特征表达
https://tech.meituan.com/2018/11/15/reinforcement-learning-in-mt-recommend-system.html
二、LLM 如何重新定义推荐系统
Large Language Model 大型语言模型
基于深度学习的自然语言处理模型,具有强大的文本生成和理解能力。LLM 通过在大规模语料库上进行训练,可以学习和模拟人类语言的规律和习惯,从而生成和解析自然语言文本。LLM 有着广泛的应用,如文本生成、数据挖掘、智能问答、兴趣分析等Modality-based Recommender Models 基于模态的推荐模型。
近年来 NLP、CV 和模态预训练大模型技术蓬勃发展,特别是 Transformer 架构出现,成为自然语言处理(NLP)领域的主流架构。Transformer 诞生了知名的大语言模型 LLM : Google 的 BERT 和 OpenAI 的 GPT。它们技术上取得了一系列革命性成果,对多模态(文本和图像)建模能力产生了质变。业界也在探索:如果用先进的模态编码器表征物品是否能取代经典的 ID embedding 模型? 下面论文介绍了不同预训练模型和 IDRec 对比测试效果,同时深入地探讨模态编码器该如何实现更好的物品表征和用户表征的策略。
Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited
论文出处: https://arxiv.org/pdf/2303.13835
以 Transformer 为基础的 LLM,从架构设计角度,目前和将来要应用到推荐系统 (Recomand System),业界和学术界给出了以下几种可行的模式:
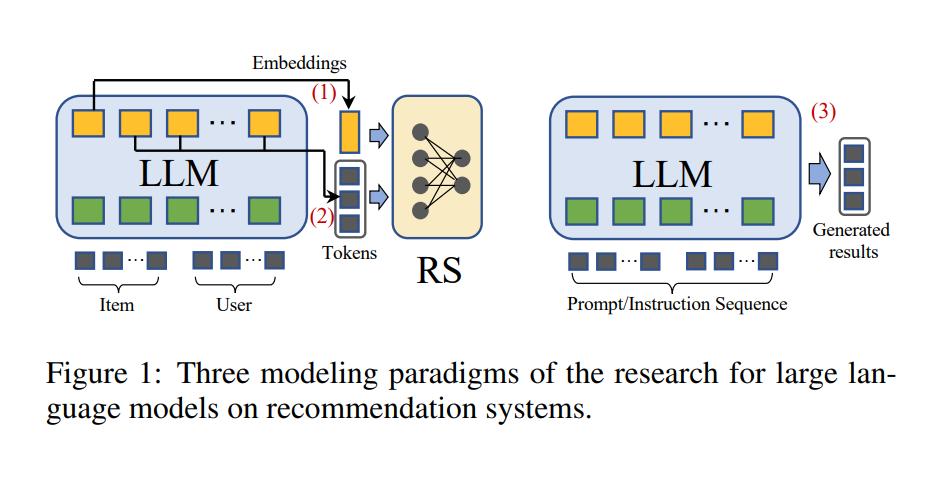
LLM Embeddings + RS
图中 (1): 将语言模型视为特征提取器,将物品和用户的特征输入到 LLM 中并输出相应的嵌入。传统的 RS 模型可以利用知识感知嵌入进行各种推荐任务。
LLM Tokens + RS
图中 (2): 与前一种方法类似,根据输入的物品和用户的特征生成 Token。生成的令牌通过语义挖掘捕捉潜在的偏好,可以被整合到推荐系统的决策过程中*LLM 作为 RS。
图中 (3): 与 (1) 和 (2) 不同,这个范式的目标是直接将预训练的 LLM 转换为一个强大的推荐系统。输入序列通常包括简介描述、行为提示和任务指示 (可以简单理解为直接通过 Prompt 告知 LLM 完成推荐系统的整个流程)。输出序列预测一个合理的推荐结果。
相关的研究 https://github.com/WLiK/LLM4Rec-Awesome-Papers
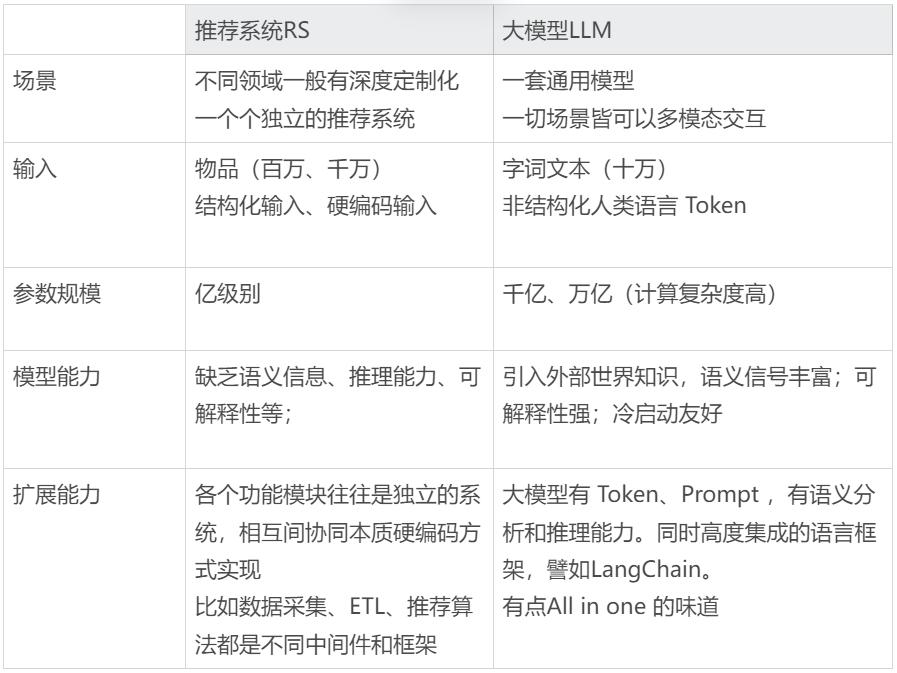
LLM RS VS 传统的 RS
如果我们用大模型实现推荐功能,LLM 会有哪些特点和天然优势?我们从下面各个维度大体来介绍和对比下:
下面我列举了一些传统的推荐系统架构,其实它们的设计和维护还是非常复杂的:
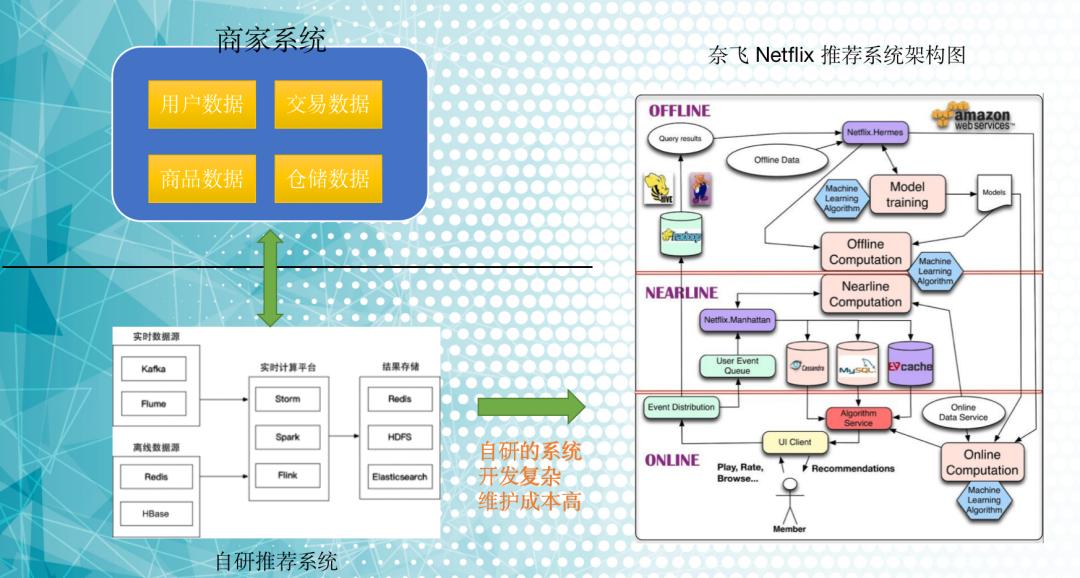
简单总结下传统的推荐系统比较“重”的点:
- 每个功能模块几乎都是独立中间件系统,每个系统单独部署和研发人员的维护:
比如数据采集,可能来自 PDF、Execl 文档,也可能来自 HTTP 上报的用户日志文件;
实时计算、离线计算调用一些 Flink、Storm 的流式引擎;
结果有可能存储到缓存系统 Redis,搜索引擎 ES,分布式文件储存 HDFS 的不同介质;
- 推荐算法可能用到 TensorFlow、Pytorch 等机器学习框架。
- 越是用户量大,数据量的推荐系统,它的架构涉及的层级和部署中间件服务就复杂,就像上面奈飞 Netflix 推荐系统。
推荐系统各个模块协同几乎都是定制化,也就是'硬编码'形式,各领域推荐系统都是独立造轮子,比如电商平台的推荐系统,抖音微信用户社交的个性化推荐,也许他们底层高度相似,但却是两套完全不同的推荐系统在开发和部署。
LLM 虽然使用它的流程和涉及功能模块确实也很复杂。从产品角度看,它确实变成了通用的产品使用场景。大模型有很多,但是通过 LangChain 来调度使用 LLM 的过程却是高度一致。
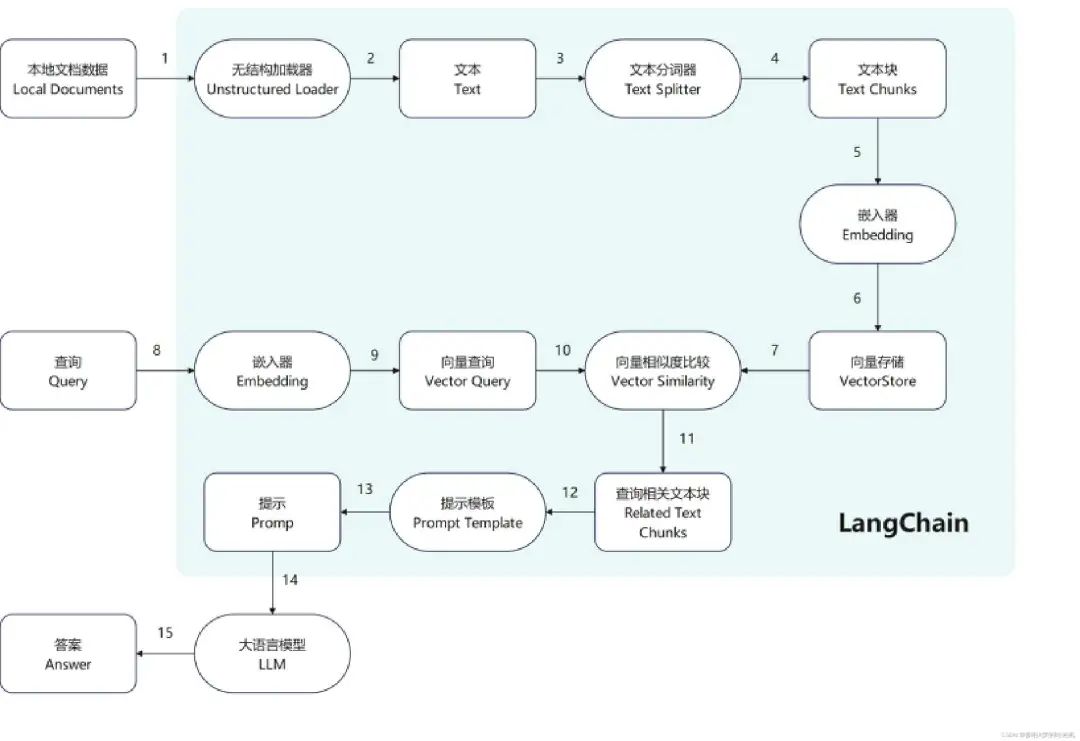
LangChain 管理下 LLM 的应用过程
什么是 LangChain
LangChain 是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,集成额外的资源,例如 API 和数据库。
从功能模块视角对比,LangChain 的 Data Connection 就有点类似于推荐系统里数据采集、数据挖掘、特征工程的过程。
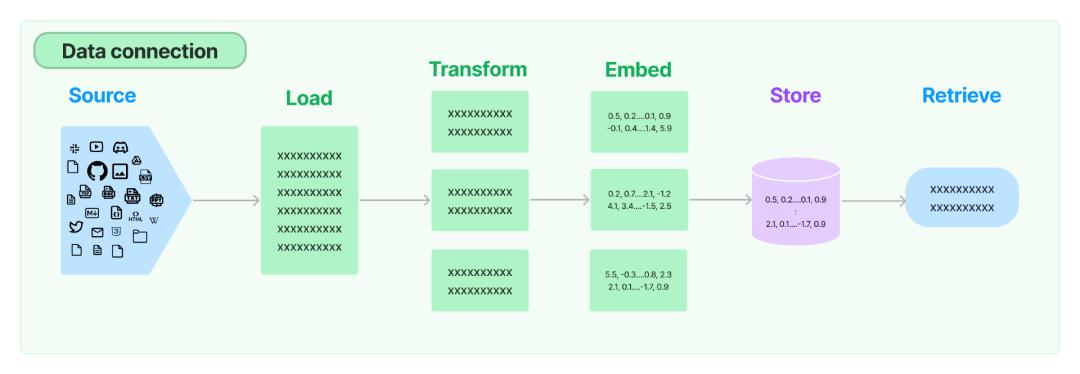
Data Connection给 LLM 提供了所需要的特征数据。它提供了加载、转换、存储和查询数据的构建块:
Document loaders :从许多不同来源加载文档Document transformers:拆分文档、将文档转换为问答格式、删除冗余文档等。Text embedding models:获取非结构化文本并将其转换为浮点数列表Vector stores:存储和搜索嵌入数据Retrievers:Query your data
Data Connection 将非结构化的数据转化成向量形式储存,和推荐系统的数据采集、数据挖掘、特征工程过程很类似。而且也用到了 Embed ,这和推荐系统 ID Embedding 原理一样,不过向量化过程中,是一种多模态编码的 Embeding,学术界叫做 MoRec。
更多 MoRec 介绍分享 https://zhuanlan.zhihu.com/p/633182030
推荐算法、推荐结果 VS LLM 输入 输出我们再来看 LangChain 完整的架构图:
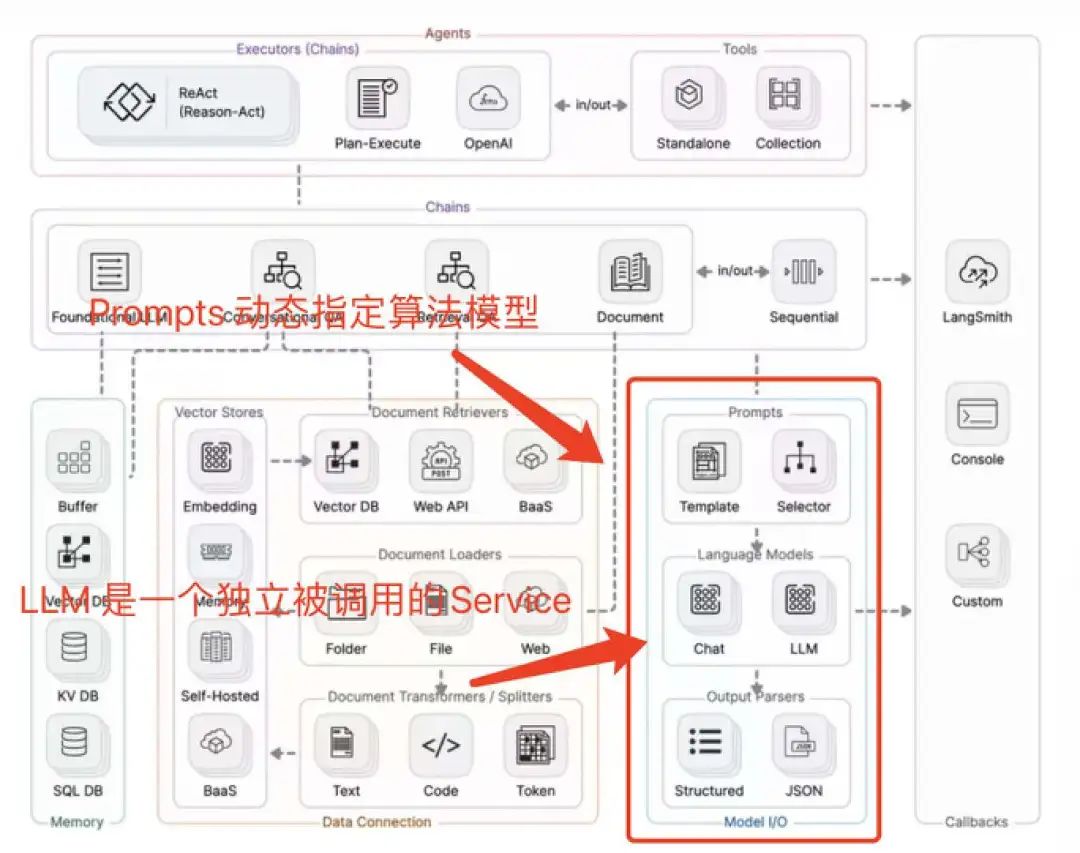
我们聚焦调用 LLM 的输入部分,这里有两个值得探讨部分:
1、LLM 本身具备语义推理能力,我们在构建不同的 Prompt,甚至指定想要的推荐算法模型来处理数据?现在推荐系统都是提前预定好数据模型和算法。
2、LangChain 像插件动态调用不同的 LLM,LLM 变成了独立的 Service,用 LLM 做推荐服务,推荐系统就可以面向所有场景的 PaaS 化。
系统设计架构走向 PaaS
PaaS Platform as a Service,平台即服务 , 把平台作为一种服务提供的商业模式
GPT、LLama 等 LLM 大模型除了 AI 技术突破的革命,同时把强大的 AI 能力普遍以 PaaS 形式开放,让业界"人人"都可以用上 AI。对于使用者现在只需要关注 Token 和算力,以更精准的方式去索取 AI 的赋能。AI PaaS 已经是未来的趋势。

我认为将来会有专门的推荐引擎出现,并且提供一站式服务,让搭建推荐系统成本越来越低。越来越多的云计算公司提供全场景的推荐 PAAS 服务。创业公司或者企业不需要自己从 0-1 组建推荐研发团队,创建一个新的本地推荐系统。完全可以购买推荐系统云服务,让搭建推荐系统不再是技术壁垒。
研发团队规模大大减少
到那时, 公司可能不在需要推荐算法开发工程师了。只要你理解推荐算法原理, 理解 AI 和会使用 AI 工具 ,一般的研发工程师,通过采购推荐 PaaS 服务,就可以使用平台级的推荐服务。这样,我预估整理在 AI 时代,企业内部推荐团队结构变化。
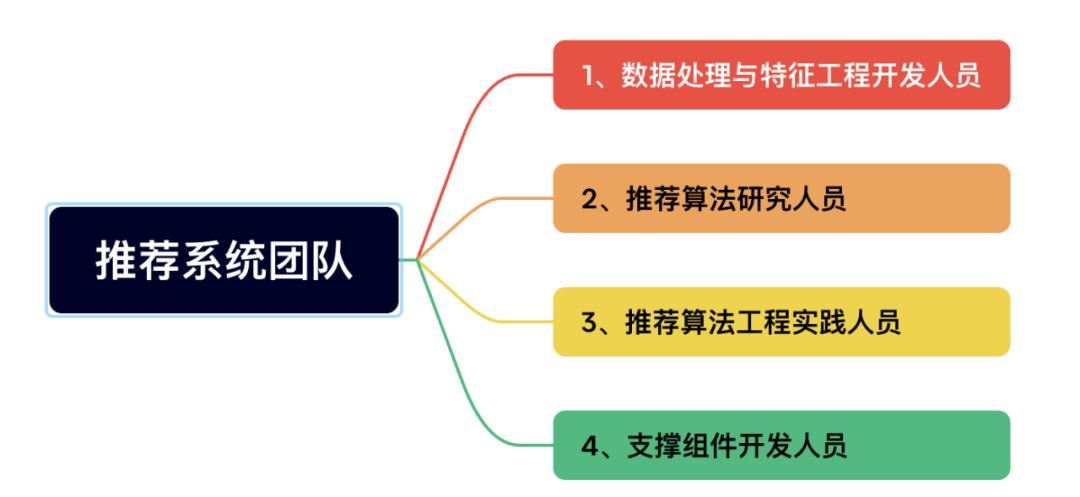
目前推荐团队主要人员组成

未来 AI 时代推荐团队可能的转型
从上面看到,未来参与具体场景推荐虽然增加一部分 AI PaaS 费用成本。不过,研发的团队人员、成本会急剧降低。从下面市面上推荐系统人才需求很明显看到,一些大型公司花在研发成本一年过百万,甚至过千万再正常不过的事。
技术应用门槛大大降低
现在主流推荐系统,研发成本非常高昂,加上对人才本身要求高,市面上招人门槛也高。另外一方面,真是因为推荐系统复杂,技术门槛高,只能稍有规模,甚至是平台级公司有这个能力打造完整可用的推荐系统。一般企业就算有场景需求,往往因为投入远远大于产出而选择放弃。如果一些传统的电商企业,虽然有完整的用户画像、订单画像,丰富的商品。但是本身研发人员很少甚至有的连研发团队没有,不可能像淘宝,京东一样做猜你喜欢,关联推荐这样功能。而且,还有一个非常重要点是推荐系统本身提供的服务是有试错成本,它往往不断地优化和调试提供推荐的精准度,那就是更难直接产生经济价值。
还有一点也可以大家思考下:现在主流推荐系统从实现原理和用到技术框架,70%-80% 软硬件,包括算法都是几乎一样。但每家企业都是独立开发一整套推荐系统,这算不算是重复造轮子呢?
未来,AI LLM 全场景能力给推荐系统赋予了更多 PaaS 的能力,会让更多有需求和场景企业用得上推荐服务。最完美的情况就是:企业按自己数据规模,推荐的精细度,付费得到匹配自己相应的推荐服务,避免浪费也避免重复造轮子。下面是我整理的理想化的推荐 PaaS 原型:
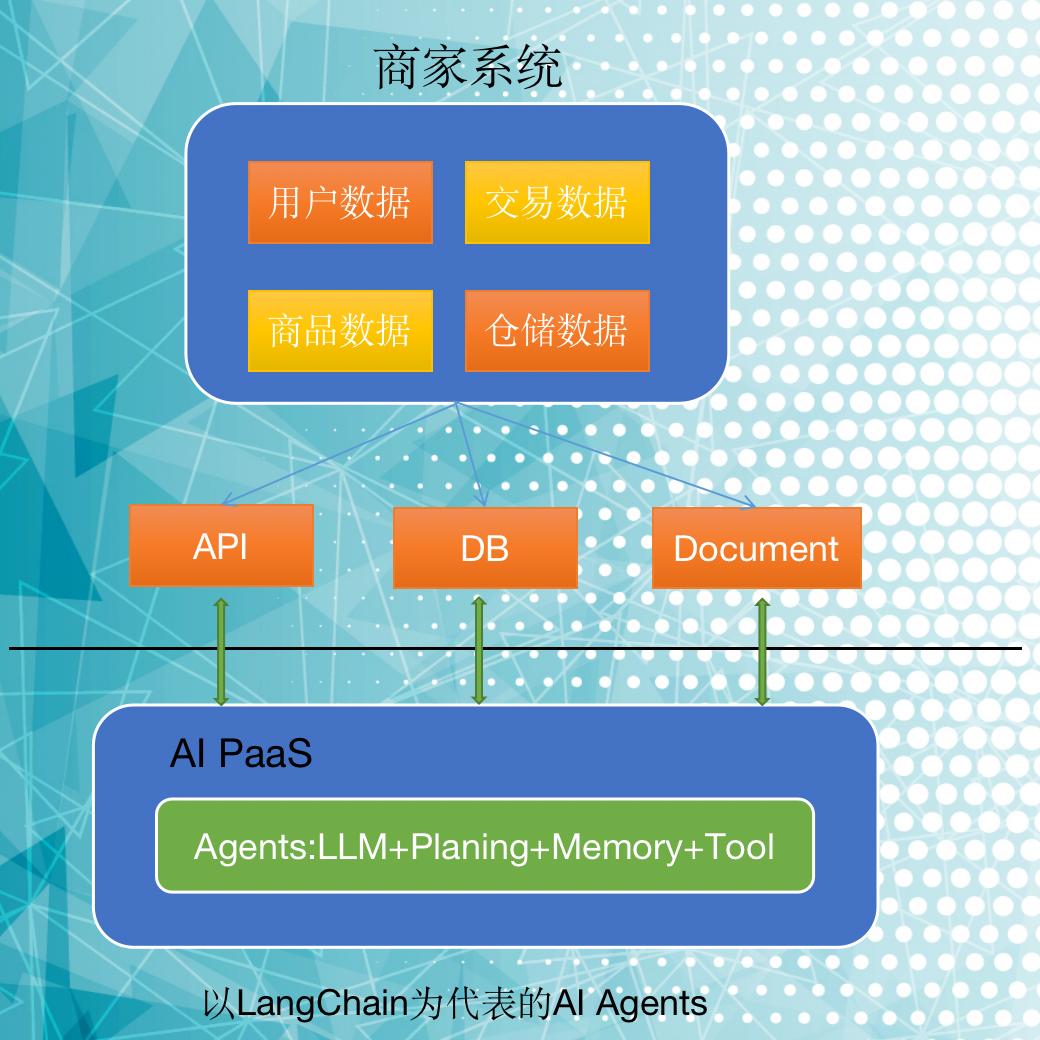
新的商业模式和应用场景
推荐系统如果可以 PaaS 化,很多有推荐需求的领域的落地就有了可能。特别是那些非平台级的企业,他们可以以更多的成本和接入门槛来从推荐价值中收益。
因为推荐应用场景实在广泛,我从了解电商领域简单做了分析,着重列举了私域的需求:
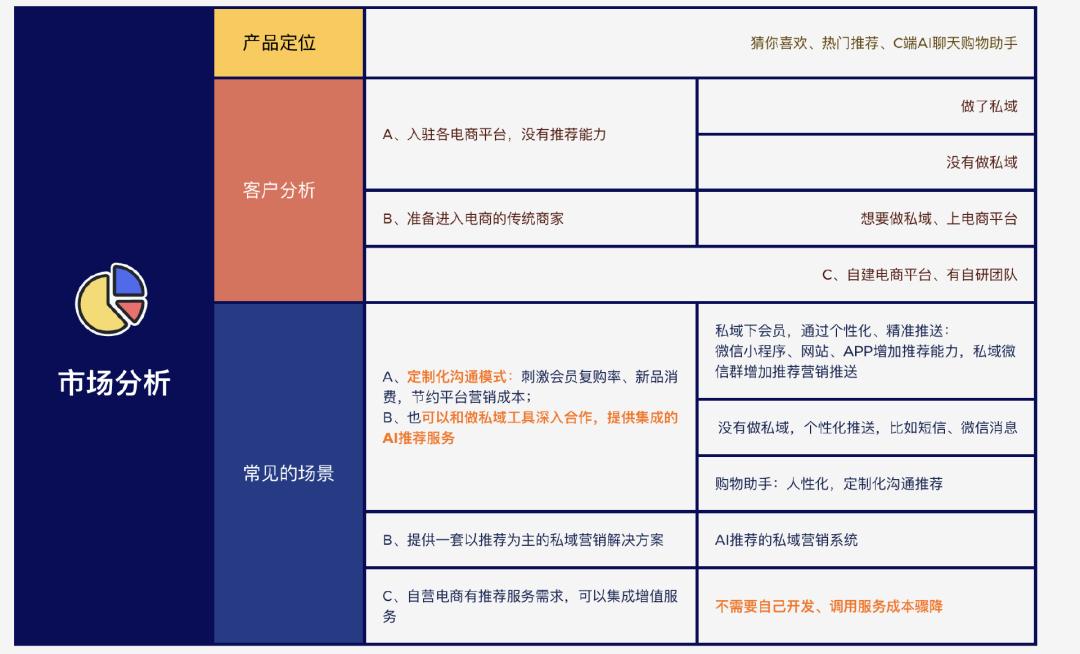
另外,因为 ChatGPT 等优秀多模态应用的创新,很多科技公司在摸索具备商品 AI 推荐能力的聊天助手。借助 AI LLM 强大的语义分析和推理功能,深度挖掘用户需求。

国外创业公司开发有 AI 推荐的电商助手
前沿的 AI 大模型推荐系统展望
我们看最新的 Gemini 1.5 Flash 给我们的答案:
目前,一些云服务商正在探索 LLM 与 Recommendation System 的结合,例如Google Cloud: 提供 Vertex AI 等服务,支持用户使用 LLM 进行定制化推荐系统开发。
Amazon AWS: 提供 Amazon SageMaker 等服务,支持用户使用 LLM 进行推荐模型训练和部署。
微软 Azure: 提供 Azure OpenAI Service,方便用户访问和使用 OpenAI 的 LLM。
总而言之,目前没有专门针对 LLM 进行推荐的云服务商,但一些云服务商正在积极探索 LLM 在 Recommendation System 中的应用,未来可能会出现专门的 LLM Recommendation System 云服务商。
Gemini 预言未来出现 LLM Recommendation System 云服务商,AI 和我的看法是一致的。如果有兴趣了解更多,参考下面的链接:
https://github.com/WLiK/LLM4Rec-Awesome-Papers
三、AI Gemini 实现通用推荐服务的案例
我们基于 LLM 直接充当 RS 的模式,用 Gemini 简单实现常用场景的推荐系统这里我演示了几个最经典的推荐算法,这些算法大部分场景频繁使用。
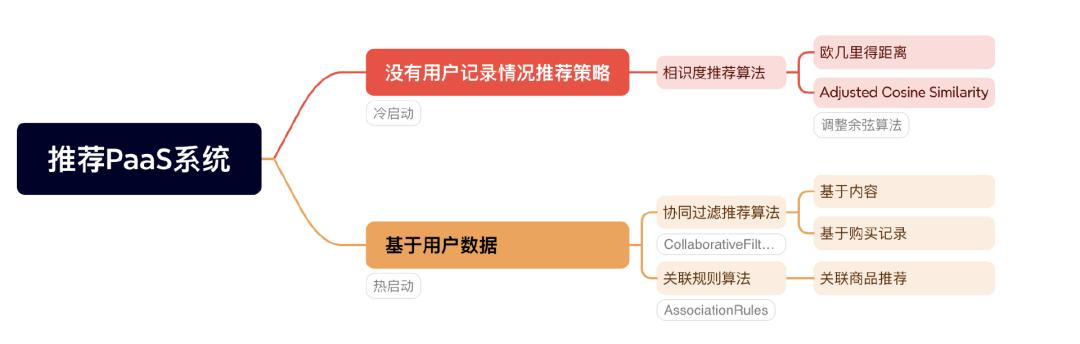
说明:推荐策略分为两种,一种甲方没有初始化的数据。比如系统中缺乏新用户的历史行为数据,因此无法了解新用户的兴趣和喜好,推荐系统就采用冷启动的策略。从冷启动来说,已经有大数据模型的 LLM 确实是个天然优势。目前看像 OpenAI,Google AI 他们拥有的海量数据,在已经有很多公开数据积累的行业,就算是新用户推荐,冷启动效果也是不错。
冷启动案例:相识度推荐
在没有用户数据情况下,我们基于 欧几里得距离 的相识度推荐算法,案例用户输入一个书名,推荐用户可能喜欢的书籍,效果如下:
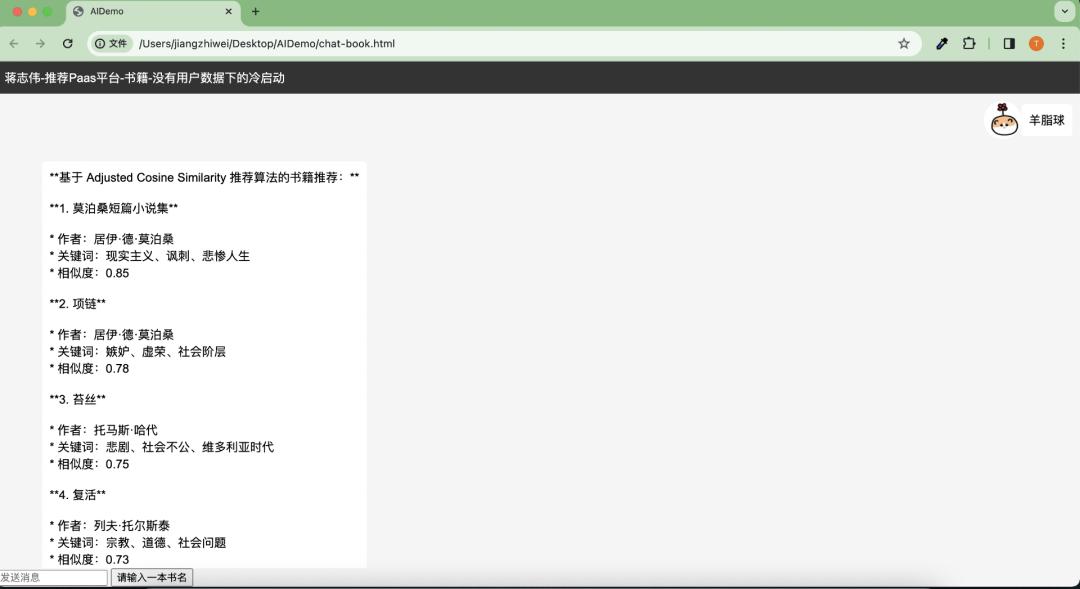
热启动:协同过滤、关联规则推荐
还有一种叫热启动,就是基于甲方已有用户画像,商品数据,用户记录,历史订单等等。可以做到更精准、有价值的推荐,过去作者在美团、Qunar 也做过类似的推荐系统。
基于用户内容推荐
在提供用户访问数据情况下,我们基于协同过滤推荐算法案例:给一组用户看过并且评分过的电影数据,在给 LLM 的输入,我们构造这样的 Prompt 让 AI 去推理和选择算法模型。
基于用户间一些相识向量维度,推荐给所有用户没看过的电影,效果如下:
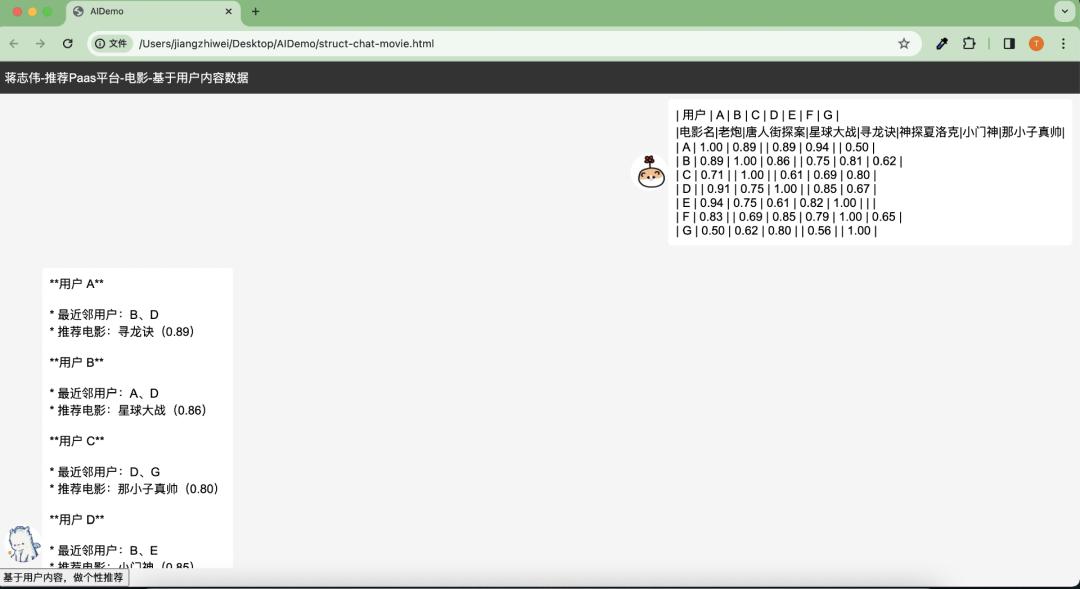
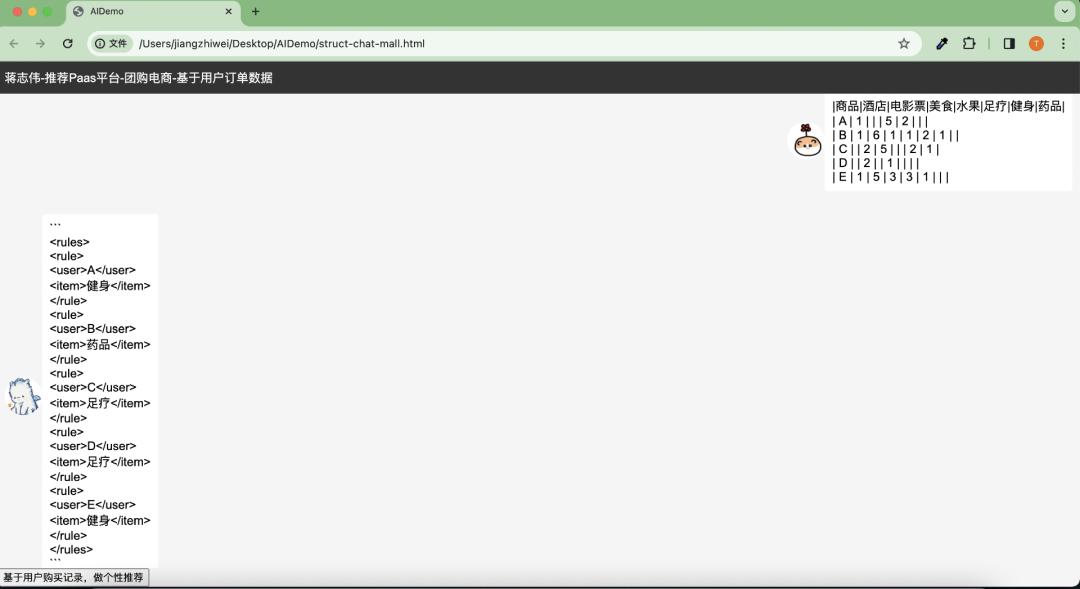
热启动:基于用户历史订单推荐商品
在提供用户订单数据情况下,我们格式化订单和优化 Prompt,基于协同过滤推荐算法,推荐复购率高的商品给客户案例:假设我们有用户的购买订单表,推荐给每个用户没买过的商品,效果如下:
美团团购第一版猜你喜欢,主要就是基于商品 ID 特征的协同过滤 算法实现的,效果很好,产生了超过 40% 商品下单复购率。这个数据蛮惊人,事后总结看,主要在于我们拥有精准的用户画像,海量消费行为记录,这样情况下的热启动,推荐准确度自然会高。
Github 相关源代码,分别写了 Java、Python 两个 Demo。所以回到上文,未来推荐系统也许真的只需要工程实践研发工程师足矣,剩下的交给 AI,交给推荐 PaaS 吧。
Java 、Python 利用 Google Gemini 分别实现的推荐服务
https://github.com/laziobird/LLMRecomand
最近 Google LLM 从 Gemini 1.0 Pro 更新到 Gemini 1.5 Pro
我重新在 Python 里面更新了 gemini-1.5-flash 的实例
代码里面还演示了关联规则 算法给用户进行组合商品推荐。这个经典场景是当年亚马逊的营销真实案例:
https://zhuanlan.zhihu.com/p/615163335
《啤酒与尿布 -- 神奇的购物篮分析》作者:“啤酒与尿布”是真实的案例!!!
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。




