







快手今天放了个大招,开源了自家的图像生成模型——"可图 Kolors"。这可不是一个普通的模型,它在数十亿的文本图像对上进行了训练,搭载了通用语言模型(GLM)作为文本编码器,支持中英文双语提示词,还能处理长达256个token的上下文。
可图 Kolors 特色一览:
中英双语支持:采用通用语言模型(GLM)作为文本编码器,让模型不仅精通英文,也能完美理解并运用中文提示词。
长文本处理能力:支持长达256个token的上下文长度,让创作者能够细致描绘心中所想,无论是复杂场景还是丰富故事。
海量数据训练:在数十亿个文本图像对上进行训练,模型拥有庞大的知识库,能够生成多样化且精准的图像。
中国文化元素优化:特别针对中国的文化元素进行了优化处理,使得生成的图像更贴近中国文化特色,满足本土化需求。
中文文字生成:"可图 Kolors"不仅能理解中文,还能在生成的图片中嵌入中文文字,为图像增添更多表达力。
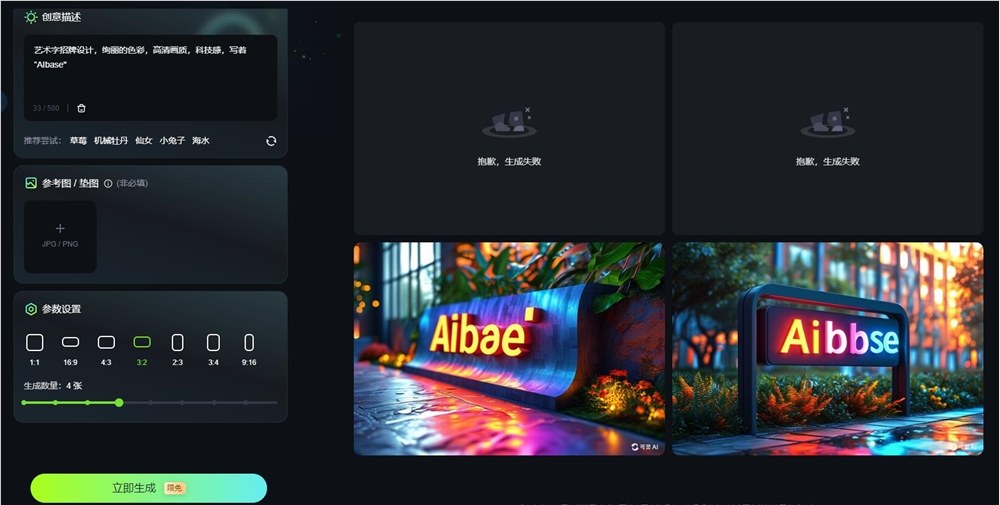
AIbase测试一下,发现,目前可图在图片中插入中文表现会更好,基本都可以正确输出,但英文的话,容易少字或错字。
可以看到,上面生成的躺平小猫,中文完全没问题,但我换成“AIbase”就会有缺字漏字的情况。就输出中文而言,可图表现可圈可点,不过注意,文字不能太长,太长的话,容易出错。
这个模型不仅仅是一个简单的工具,它背后有快手强大的技术支撑。它在海量数据上训练,对中国文化元素有特别优化,生成的图像更有中国味。这不仅仅是技术上的突破,更是文化上的传承。
开源计划还包括了CN(ControlNet)支持、LoRa(低秩适应)、IPA(图像提示适应)和ComfyUI直接支持,这些都是为了让你的创作过程更加流畅和个性化。
技术细节:
"可图 Kolors"基于SDXL模型架构,并融合了ChatGLM256技术,以增强双语理解和文字生成能力。
值得注意的是,运行此模型需要较大的显存,大约19GB,这可能对硬件设备有一定要求。
快手这次开源"可图 Kolors",不仅是对技术社区的贡献,更是对创作自由的一次大胆推动。这表明了快手在AI技术上的决心和实力,也让我们看到了AI在艺术创作上的无限可能。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。





