







登录就送500w tokens!1块钱 100w tokens!一降再降!!仅需0.0008元/千tokens!
没错,互联网价格战熟悉的“味”,已经悄无声息的打到了大模型的战场。
技术狂飙了一年,大模型公司们早就按捺不住要搅弄商业风云的心,5月份,多家大模型产品宣布了密集的降价策略。
严格来说,是堪称为大模型界“拼多多”的DeepSeek,率先点燃了价格战的引线。
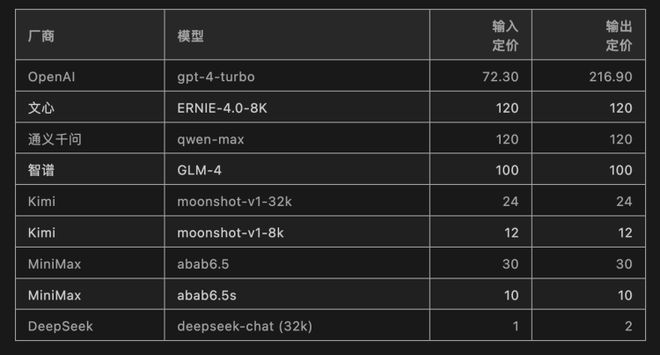
5月6日,DeepSeek官网推出了“高性价比”的大模型,将旗下的大模型DeepSeek-V2的价格降到了每百万token输入1元、输出2元(32K上下文),能力对标GPT-4、llama 3-70B,价格仅为GPT-4的近1%。开发者登录 DeepSeek 开放平台送 500万 tokens。

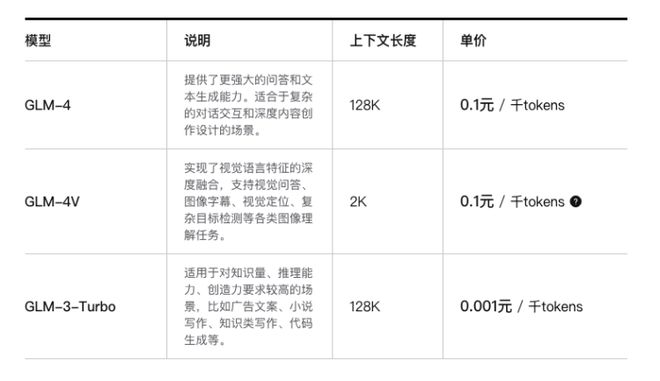
智谱第一个不服。5月11日,智谱AI调整了旗下入门级大模型GLM-3-Turbo(上下文长度128k)的价格,从0.005元 / 千tokens降低到0.001元 / 千tokens。此外,开放平台新注册用户获赠从500万tokens提升至2500万tokens(包含2000万GLM3-Turbo和500万GLM4)。而GLM-3 Turbo Batch批处理API还将进一步便宜50%——0.0005/千 tokens,也就是1元200万tokens。
5月15日,火山引擎原力大会上,豆包高调的将本来在水面下的价格战,赤裸的搬到了台面上。
会上火山引擎总裁谭待宣布豆包主力模型在企业市场的定价只有0.0008元/千 tokens,0.8厘就能处理1,500多个汉字,比行业便宜99.3%。
现场观众的激动程度堪比听到大主播在直播间大吼:“家人们,我们把大模型的价格打下来了!”
在DeepSeek发起,几个核心厂商跟进的局面下,也彻底拉开了大模型商业竞争进入了“卷价格”的新赛段。
1
比价,用百度阿里当“活靶子”
有意思的是,大家比价归比价,都拿百度文心和阿里通义当靶子。
无论是DeepSeek、智谱还是豆包,都以文心和通义为标尺进行比价。当然,这也侧面反映了,这两个模型确实在中国大模型中,占据了很重要的位置,甚至是参照物。
虽然不谈性能只谈价格的方式无异于“耍流氓”,但对于价格敏感型的客户而言,价格基本上就是唯一的决定性因素。
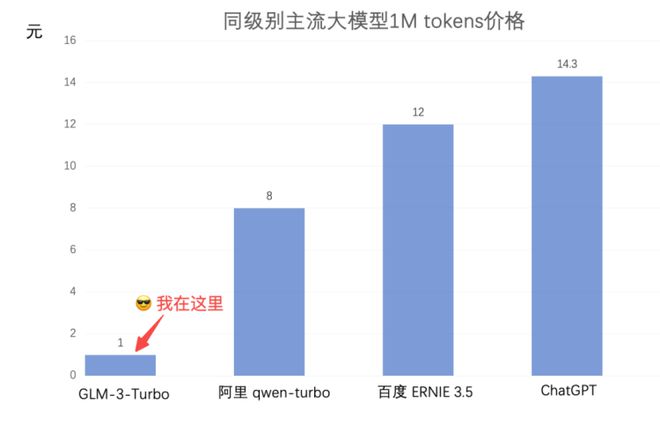
智谱在公布新大模型时,做了直观的比价图,GLM-3-Turbo的价格是阿里qwen-turbo的八分之一,是百度ERNIR 3.5的十二分之一。当然对比ChatGPT的时候,就不能抛开性能,只比价格了。
同样,豆包在发布豆包通用模型pro的价格时,也拉来了百度和阿里的对标模型作为价格对比。基本上,行业价格等于ERNIE和Qwen的平均价格。
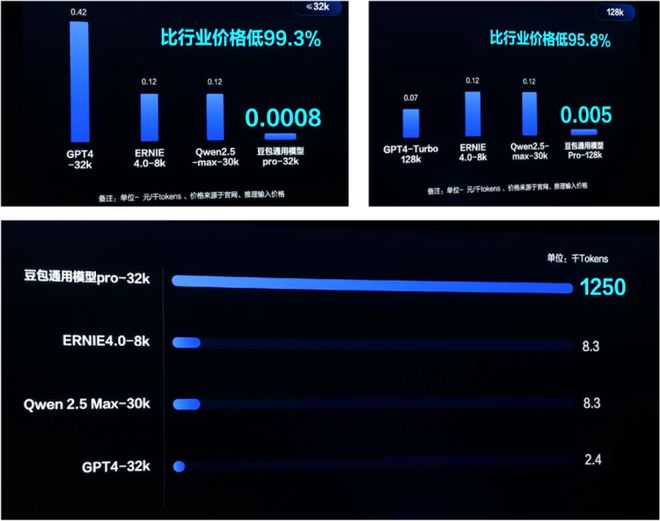
还有卷的更狠的,直接拉国内外的主流模型们进行集体比价。

而针对被当活靶子以及是否参与价格战的问题,百度在豆包宣布全面降价的下午便回复道:“文心大模型日均处理Tokens文本已达2490亿,并强调使用大模型不应只看价格,更要看综合效果。”
为了能够让客户更了解低价的现实意义,各家大模型厂商都在努力“接地气”。
1块钱在现实世界可能连个包子都买不到,但是在智谱,你能写1万条小红书(以350字计算);在豆包,你能读三本《三国演义》;在DeepSeek,一位普通开发者充50块钱能用好几年。

不仅卖,他们还免费送。
开发者登录 DeepSeek 开放平台就送 500 万 tokens,而智谱似乎就是要跟DeepSeek硬刚,随即宣布新注册开放平台用户赠送额度提升500%。开放平台新注册用户获赠从500 万tokens提升至2500万tokens(包含2000万入门级额度和500万企业级额度)。
有开发者表示:“如果只是自己开发测试根本用不完,热闹都是他们的,我们就负责占便宜。”
面壁智能直接喊出了“不降价,0元不限量”的活动。不过这是因为模型本身免费开源,且部署在端侧,利用终端设备算力,无需调用云端API。
有开发者向硅星人表达了自身感受:“以前薅服务器和存储空间,现在薅tokens,不出意外的话,后续几家主流的模型厂商都会跟进,我们未来3年可能都不用买tokens了。”
1
谁是最便宜的大模型?
那么问题来,到底谁是最便宜的大模型?
硅星人根据各家厂商的官方信息,汇总整理了部分大模型API的价格,直观的对比了价格,话不多说,直接上图(这可能是市面上最全的比价图了):
从图表中整理的情况来看,如果按照绝对值计算,豆包pro32k是目前市场价格最低大模型,但DeepSeek-V2的上下文文本长度为128k,对比下来,可以说是性价比最高的大模型了。
价格战对于每一代的互联网人而言,都并不陌生,降价策略通常被视为吸引更多用户、增强用户黏性和市场份额的一种有效手段,但同时,也常常逃不开“拿钱换增长”的恶性循环。
谭待讲道:“用亏损换收入是不可持续的,所以我们从来不走这条路”。
DeepSeek v2版本发布时,其员工也表示:基本纯靠模型结构创新(MLA+DeepSeekMoE)+ 超强Infra,且“目前就是大规模服务的价格,不亏本,利润率超50%”。
价格低还有利润?是怎么做到的?
影响大模型推理价格的降低的因素有很多,比如技术进步和优化就是一个直接的原因,不少开发者惊叹于幻方是怎么兼顾模型效果和成本的。
首先源于DeepSeek本身的硬实力,就是我们俗称的“有卡”。根据幻方官方信息,其幻方 AI 智能超算集群配备了 1 万张英伟达高性能的 A100 计算卡,硬件和计算资源可能也是DeepSeek能够保持低价的原因。它也是国内为数不多非大厂拥有万卡的公司。
其次是来自于架构和算法上的创新。这一点和豆包能低价是相同的。
谭待介绍道:“火山引擎在技术上有非常多优化手段,可以降低大模型成本,此外在工程上可以通过分布式推理的形式将底层算力使用得更好;另外,在混合调度方面,可以把不同负载作为混合调度,这样的成本也大幅下降。”
我们都知道,当一个行业进入了价格战阶段,就意味着产品走向了同质化。在大模型发展的早期技术的差异性还未清晰,但低价确实能够带来更广泛的渗透,于国内大模型而言,这是福还是祸?
客观上来看,大模型API价格战和推理价格的下降,有可能推动AI应用的广泛普及和创新,因为更低的成本使得更多的企业和开发者能够负担得起这项技术,也有更多的尝试空间。不过,降价能否帮助大模型厂商带来更多新增用户和付费用户,仍值得商榷。
虽然价格的降低可以短期内吸引更多用户尝试和采用AI大模型,但长期而言,技术能力的提升和创新是确保大模型应用普及和持续发展的根本。从互联网技术的发展历程中,我们可以明确看到技术创新和提升为行业带来的深远影响,这对大模型的发展同样适用。
正如移动互联网的普及并不只是因为手机价格的降低,一个重要原因是苹果推出了iPhone,将多点触控等技术引入手机,带来了新的人机交互方式,让iPhone软件生态的建立成为了可能。
价格战打到最后,受益的大概率只是少数头部企业。如果不能有效控制成本的企业若盲目加入价格竞争,无疑会丧失自身优势,陷入他人设定的竞争节奏,最后又是一轮行业洗牌。
不只要“卷”价格,更要“卷”技术,“卷”产品,全方位的“卷”,才能找到新出路。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。





