







今年 10 月,智谱在 CNCC2024 大会上推出了他们在多模态领域的最新成果——端到端情感语音模型 GLM-4-Voice,让人和机器的交流能够以自然聊天的状态进行。
据介绍,GLM-4-Voice 能够直接理解和生成中英文语音,进行实时语音对话,在情绪感知、情感共鸣、情绪表达、多语言、多方言等方面实现突破,且延时更低,可随时打断。
日前,智谱团队发布了 GLM-4-Voice 的研究论文,对这一端到端语音模型的核心技术与评估结果进行了详细论述。

论文链接:
https://arxiv.org/abs/2412.02612
GitHub 地址:
https://github.com/THUDM/GLM-4-Voice
GLM-4-Voice 是如何练成的?
与传统的 ASR + LLM + TTS 的级联方案相比,端到端模型以音频 token 的形式直接建模语音,在一个模型里面同时完成语音的理解和生成,避免了级联方案“语音转文字再转语音” 的中间过程中带来的信息损失,也解锁了更高的能力上限。
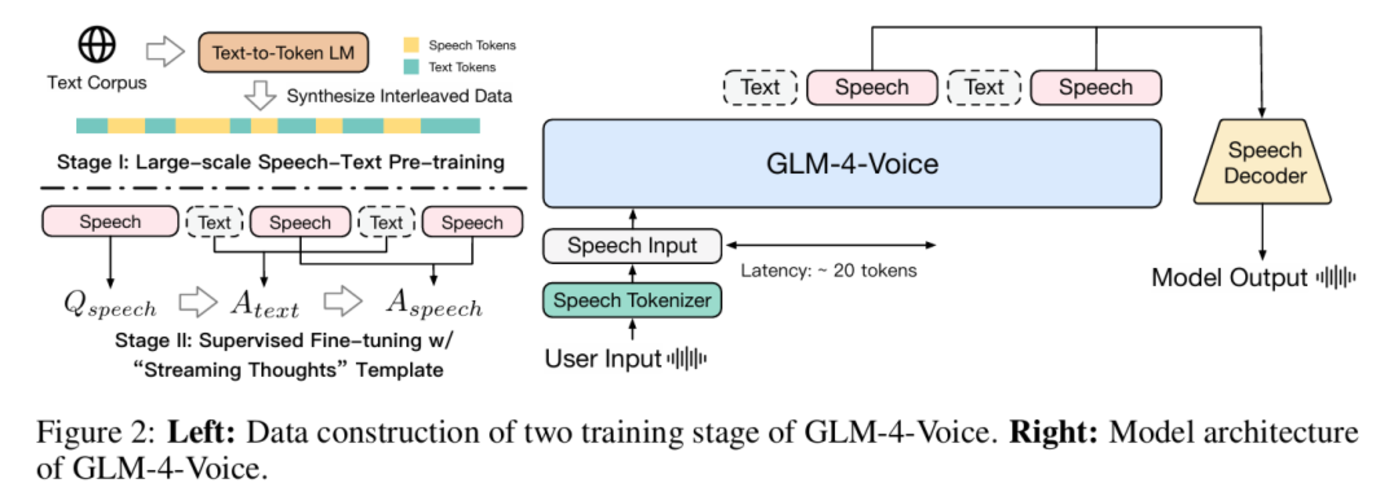
图|GLM-4-Voice 模型架构图。
GLM-4-Voice 由三个部分组成:
- GLM-4-Voice-Tokenizer:通过在 Whisper 的 Encoder 部分增加 Vector Quantization 并在 ASR 数据上有监督训练,将连续的语音输入转化为离散的 token。每秒音频平均只需要用 12.5 个离散 token 表示。
- GLM-4-Voice-Decoder:基于 CosyVoice 的 Flow Matching 模型结构训练的支持流式推理的语音解码器,将离散化的语音 token 转化为连续的语音输出。最少只需要 10 个语音 token 即可开始生成,降低端到端对话延迟。
- GLM-4-Voice-9B:在 GLM-4-9B 的基础上进行语音模态的预训练和对齐,从而能够理解和生成离散化的语音 token。
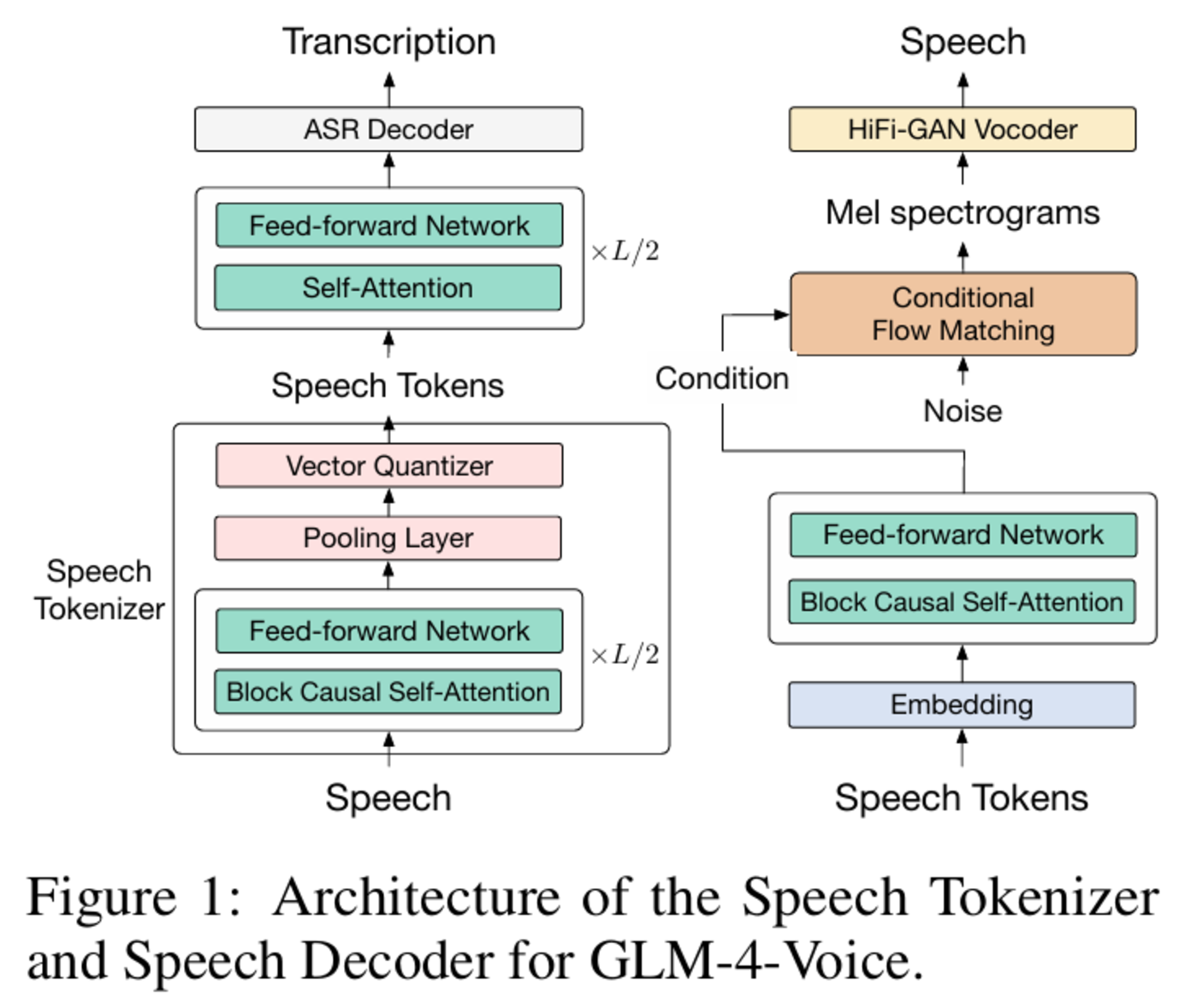
图|GLM-4-Voice-Tokenizer 和 GLM-4-Voice-Decoder 的架构。
预训练方面,为了攻克模型在语音模态下的智商和合成表现力两个难关,他们将 Speech2Speech 任务解耦合为“根据用户音频做出文本回复”和“根据文本回复和用户语音合成回复语音”两个任务,并设计两种预训练目标,分别基于文本预训练数据和无监督音频数据合成语音-文本交错数据以适配这两种任务形式。
具体而言,模型的预训练包括 2 个阶段。
第一阶段为大规模语音-文本联合预训练,在该阶段中 GLM-4-Voice 采用了三种类型的语音数据:语音-文本交错数据、无监督语音数据和有监督语音-文本数据,实现了促进文本和语音模态之间知识迁移、帮助模型学习真实世界语音特征以及提升模型基本任务方面性能方面的效果。尤其,GLM-4-Voice-9B 在 GLM-4-9B 的基座模型基础之上,经过了数百万小时音频和数千亿 token 的音频文本交错数据预训练,拥有很强的音频理解和建模能力。
第二阶段为监督微调阶段,旨在进一步提高 GLM-4-Voice 的对话能力。研究人员使用了两种类型的对话数据,包括多轮对话数据与语音风格控制对话数据。前者主要来自文本数据,经过精心筛选和语音合成,确保对话内容的质量和多样性。而后者包含高质量的对话数据,用于训练模型生成不同风格和语调的语音输出。
此外,在对齐方面,为了支持高质量的语音对话,降低语音生成的延迟,研究团队设计了一套流式思考架构:根据用户语音,GLM-4-Voice 可以流式交替输出文本和语音两个模态的内容,其中语音模态以文本作为参照保证回复内容的高质量,并根据用户的语音指令要求做出相应的声音变化,在最大程度保留语言模型智商的情况下仍然具有端到端建模的能力,同时具备低延迟性,最低只需要输出 20 个 token 便可以合成语音。
效果怎么样?
研究团队在基础模型评估与聊天模型评估两方面对 GLM-4-Voice 进行了性能评估。
他们首先通过语音语言建模、语音问答以及 ASR 和 TTS 这三项任务对基础模型进行了评估。
在语音语言建模任务中,GLM-4-Voice 在 Topic-StoryCloze 和 StoryCloze 等数据集上的准确率显著领先同类模型。在从语音到文本生成(S→T)的任务中,GLM-4-Voice 的准确率达到 93.6%(Topic-StoryCloze),远高于其他模型。同时,在语音到语音生成(S→S)的任务中,GLM-4-Voice 依然在 Topic-StoryCloze 数据集中获得了与 Spirit-LM 相近的高分(82.9%)。
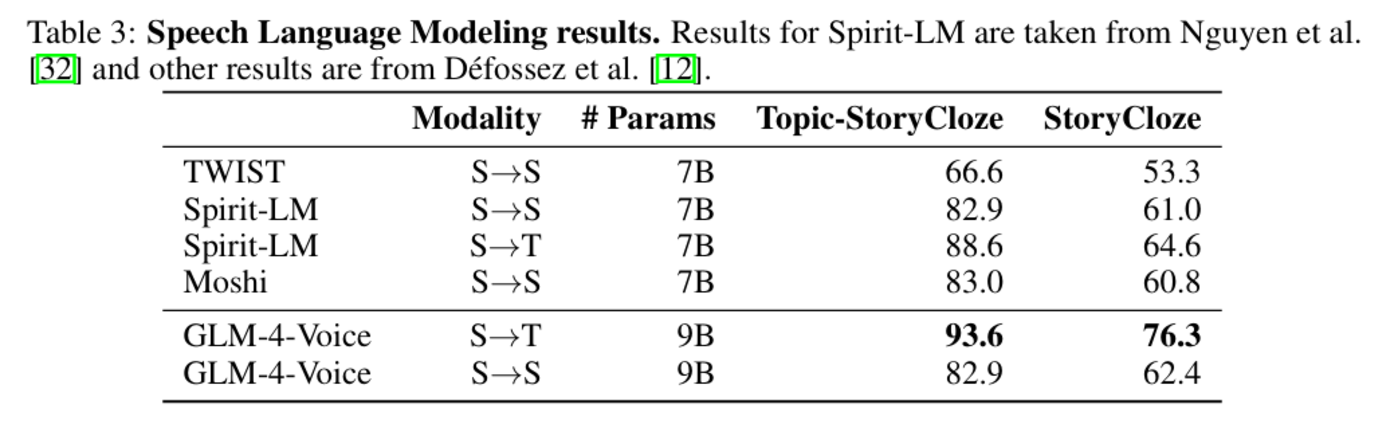
图|语音语言建模结果。
在语音问答任务中,GLM-4-Voice 在 Web Questions、Llama Questions 和 TriviaQA 等数据集上全面领先,进一步提升了模型在长上下文交互场景中的适应性。
- S→T 模态:在所有数据集中,GLM-4-Voice 均显著超过基线模型,TriviaQA 数据集中准确率达到 39.1%,相比Moshi提升了 16.3%。
- S→S 模态:在语音到语音的问答任务中,GLM-4-Voice 同样表现优异,尤其是在 Llama Questions 中准确率达到 50.7%,大幅领先其余模型。
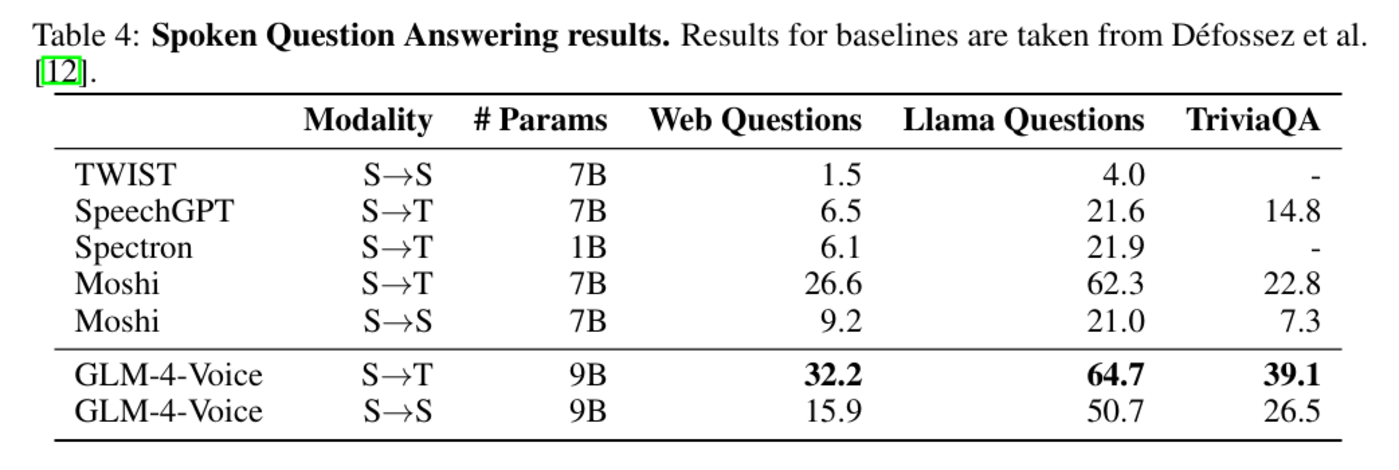
图|语音问答结果。
在 ASR 和 TTS 任务中,GLM-4-Voice 的性能也同样接近或超越专门设计的语音处理模型。
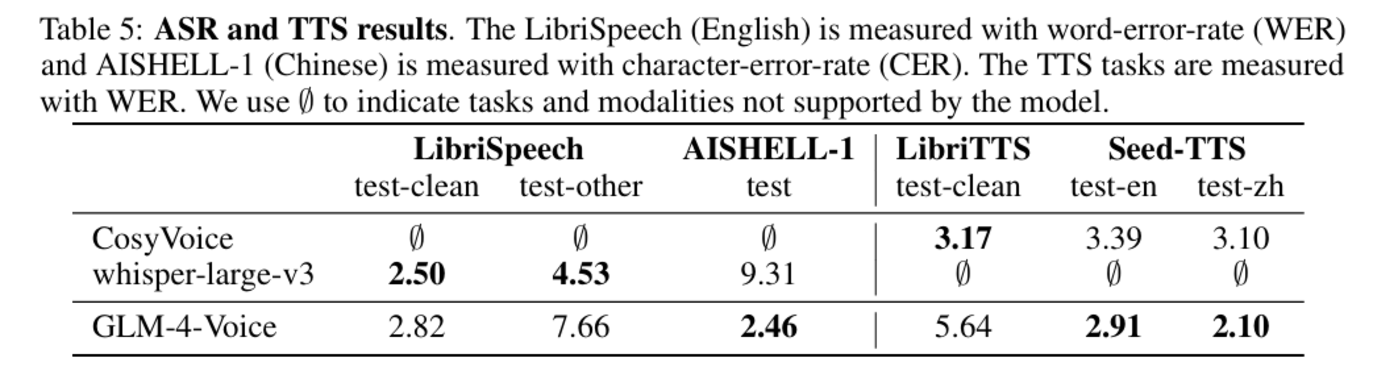
图|ASR 和 TTS 结果。
之后,研究团队对聊天模型进行了评估。
为评估对话质量,研究团队引入 ChatGPT 作为自动评分工具,对模型的回答进行多维度评价。GLM-4-Voice 在常见问题(General QA)和知识问答(Knowledge QA)两类任务中得分遥遥领先:在 General QA 中 GLM-4-Voice 得分为 5.40,相比 Llama-Omni(3.50)和 Moshi(2.42)提升显著。在 Knowledge QA 中 GLM-4-Voice 的得分同样超过其他模型。
GLM-4-Voice 在语音生成质量方面也实现了新突破。模型主观评价指标(MOS)的评分中达到 4.45,超越现有基线模型,表明 GLM-4-Voice 生成的语音更加自然流畅,能够满足用户对高质量语音交互的需求。
同时,在文本与语音对齐性测试中,GLM-4-Voice 的语音转文本误差率(ASR-WER)降至 5.74%,显示出优异的文本-语音一致性。这种能力进一步提升了模型在多模态交互中的应用潜力。
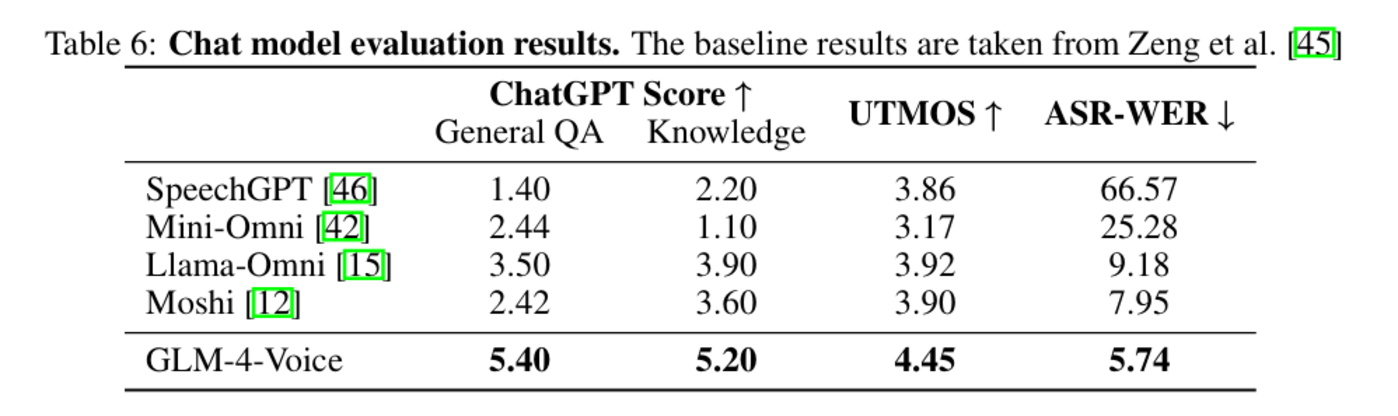
图|聊天模型评估结果。
评估结果显示,GLM-4-Voice 在语音语言建模、语音问答等任务上表现卓越,同时大幅降低了延迟,并显著提升了语音质量和对话能力,性能超过现有基线模型。这一创新为构建高性能语音交互系统提供了全新路径,开拓了更广泛的应用可能性。
目前,GLM-4-Voice 已开源,目前已有 2.4k stars。研究团队表示,这将鼓励人们进一步探索建立实用、易用的语音人工智能系统。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。




