





今年10月,《时代》杂志发布了一份「2023最佳发明」榜单,为了呼应AI浪潮,《时代》从去年开始就特别设置了「AI单元」。在今年入选的十几个应用中,排在老牌软件巨头Adobe和屠龙少年OpenAI之后的就是大火的文生视频应用——Runway Gen-2。
作为横扫奥斯卡奖项的电影《瞬息全宇宙》背后的技术公司,Runway联合创始人兼CEO Cristóbal Valenzuela在聊起自己对AI的期待时,走的也是满满的文艺风路线——「AI是一种新的摄像头,它将永远地重塑讲故事的方式,引领我们走向完全靠生成的电影长片。」
但对国内用户而言,真正让Runway等AI视频公司走入人们视野的关键性事件还要数斯坦福华人博士休学创业的项目Pika。

自Pika爆火以来,短时间内,一大波AI视频测评随之涌来,也出现了明显的口碑分化。一时间,有人高呼:“AI视频大年来了”。有乐观者认为,从文生图到文生视频,视频生成模型也迎来了属于自己的GPT时刻。不久前,「AI女神」李飞飞的斯坦福团队也和谷歌合作,推出了用于生成逼真视频的扩散模型W.A.L.T。
但也有人对此表示理性,AI视频的技术能力与商业化还有很长的路要走。Pika联合创始人兼CTO Chenlin Meng在接受采访时就坦言:“我觉得目前视频生成处于类似GPT-2的时刻。”
文生视频一直被视为多模态AIGC「圣杯」,梳理当下的AI视频赛道,尽管有着炫酷的demo。类似参与制作奥斯卡电影的实战,诸多参与竞争的行业玩家,但行业所面临的挑战依旧有很多。
本文我们将主要聊聊关于文生视频的三个关键问题:
1、文生视频背后的技术路线是什么?
2、为什么说AI视频还没到真正的GPT时刻?
3、目前的行业竞争中,谁有领先优势?
01、「圣杯」背后的两条技术路线
说起AI视频,所有的行业玩家还是要感谢他们的「老大哥」——谷歌。
市面上的文生视频模型背后其实有两条技术路线:一条从文本及图像生成中得到广泛应用的,基于Transformer模型的技术路线,另一条则是基于扩散模型(Diffusion model)。
关于第一种路线是如何诞生的,除了要感谢那篇《Attention Is All You Need》论文外,还多亏了OpenAI。
受到OpenAI基于Transformer架构和对文本数据进行大规模预训练的启发,在文生视频领域,谷歌的Phenaki、智铺AI和清华团队发布的Cog Video等都沿着这一技术路线,利用Transformer模型编码,将文本转化为视频tokens,进行特征融合后输出视频。
谷歌很早之前就已通过Phenaki开始讲述AI视频的故事了,当时的网友发出了「AI什么时候获奥斯卡」的感叹。

但基于Transformer架构的文生视频模型,缺点也非常明显,从OpenAI此前的「暴力美学」就能看出,无论从训练成本,还是从配对数据集的需求来说,都对各家提出了非常大的挑战。比如,Phenaki的研究人员在当时除了用文本和图像进行训练外,还使用了1.4秒、帧率8FPS的短视频文本。
而随着图像生成领域扩散模型的野蛮生长,研究人员又逐渐尝试将扩散模型拓展到视频领域。这之中,我们也看到,在这一波基于扩散模型而飞黄腾达的公司,也没有错过下一轮的视频生成浪潮,比如开发出了经典的文生图模型Stable Diffusion的公司 tability.ai,以及和Stability.ai关系密切的Runway。
在这条技术路径上,科技大厂和创业派可谓是百花齐放。大厂如Meta的Make-A-Video和Emu Video,英伟达的Video LDM、微软的NUWA-XL,创业派如Stable AI和Runway,都是这样的逻辑。
两条技术交替,目前扩散模型占据主流,但没有优劣之分,但从技术迭代背后,我们可以观察到明显的三大趋势。
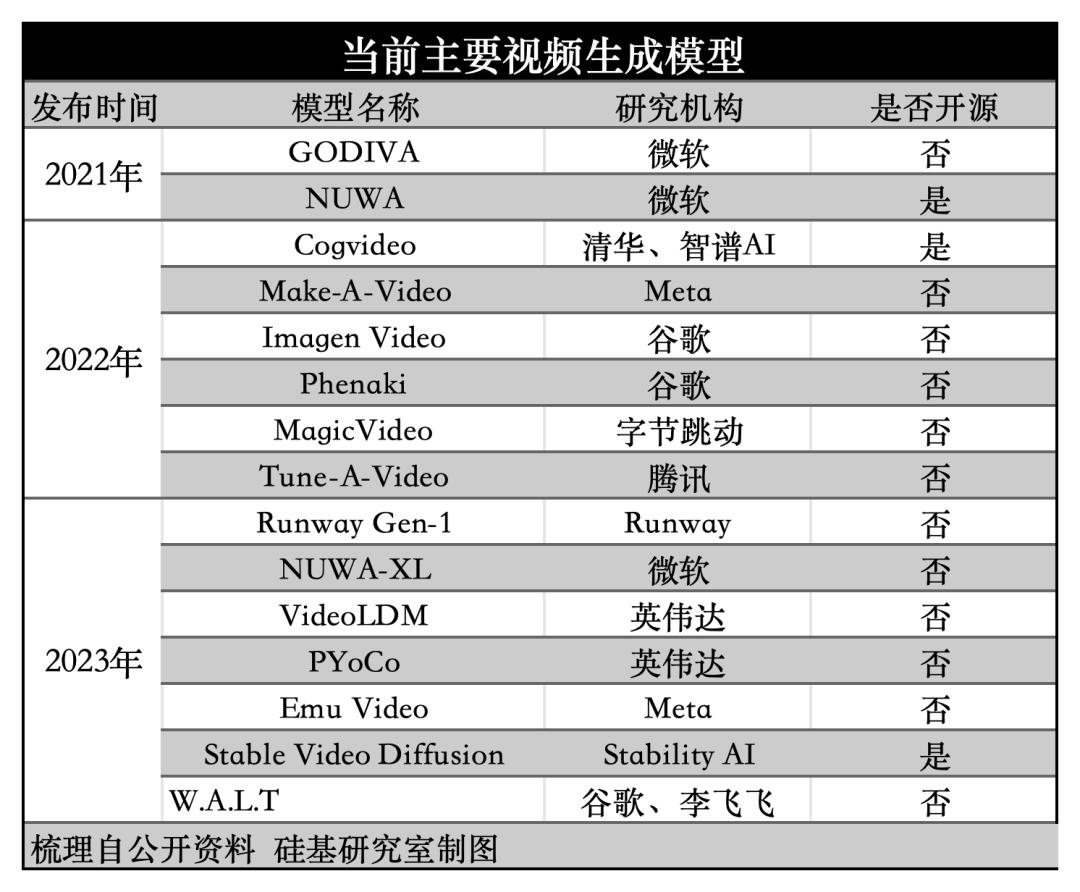
一是,从参与玩家的数量来看,整体是科技大厂居多,并没有出现如文生图模型一样的「百家争鸣」的现象,背后的原因在于从难度来看,文本>图像>视频,文生视频的门槛较高。
二是,从数据层来看,AI视频训练数据集的规模越来越大,种类也越来越丰富。以Runway Gen-2为例,其训练数据包括了2.4亿张图片、640万个视频剪辑片段以及数亿个学习示例。
三是,大多数的模型厂商,在文生视频上都选择走了闭源路线。背后的原因在于,文生视频对算力以及模型的工程化能力都很高。香港大学教授、徐图智能CEO徐东在近期的一次采访中也提到:“文生视频不是谁都能做的,开源社区可能也不太可行,因为算力要求太高了,开源社区做文生图像还可以,做文生视频可能是不实际的。”
02、AI视频远没到「GPT时刻」
Pika联合创始人兼CTO Chenlin Meng在近期接受采访时就坦言:“我觉得目前视频生成处于类似GPT-2的时刻。”
换句话说,在炫酷的demo背后,AI视频真正融入视频生产工作流,满足大众更广泛的视频类需求,还有一段距离。
首先,从目前文生视频模型产出的生成效果来看,有限的时长、较低的分辨率与生成内容的不合理依旧掣肘使用的频率。

有网友晒出了用Pika重制《泰坦尼克号》的片段, 从效果来看仍存在不少细节问题
这背后的核心原因,依旧逃不开视频场景的复杂性。
一方面,在数据端,对比收集文生图高质量数据的场景,文本生成视频模型需要通过大量数据来学习字幕、帧照片写实感和时间动态。同时,由于视频的长度是不等的,而在训练过程中将视频切成固定帧数的片段,又会破坏文本和时间之间的「对齐」,影响模型的训练。
另一方面,在视频场景中,除了要考虑空间地点信息,还需要考虑时间信息,因此如果想要具备高质量的视频生成能力,需要极强的计算与推理能力。从当下一些文生视频模型的生成表现来看,对视频对象运动连贯性的理解、对日常与非日常场景的变化等维度来看,都亟待提升。
其次,从商业模式来看,文生视频应用当前的商业模式与图片生成趋同,开启商业化的应用如Runway Gen-2也是主要按照生成量来定价。如果对照文生图应用早期商用化的进程,Runway们也还有很长一段路要走。
最后,在复杂的视频生产工作流上,行业玩家knowhow也有待提高。 视频生产过程一般分为前期和后期,前期包括了剧本创作、分镜设计、素材的拍摄与整理;而后期则是包括了粗剪、音乐、特效、调色与字幕等流程。在不同的环节,AI发挥不同的作用,模型厂商也能通过建立相关的工具链帮助创作者提质增效。
但不同环节,竞争门槛是不同的。门槛较低的如字幕添加,门槛更高则是一些视频编辑类功能,如镜头细调等。不同的视频创作者有着不同的工作流程,因此目前很难做到一家通吃。

此前出圈的《芭本海默》, 创作者主要用了Midjourney+Runway Gen-2
这也是为什么,目前我们在市面上成熟或出圈的AI视频作品背后并不是依靠一个模型或应用就能单独完成,而是多个模型+多个工具(比如ChatGPT+Midjourney+Runway)组合创造。
03、谁能吃到AI视频红利?
从文生图到文生视频,多模态能力的升级带来了新一轮AI视频的能力。但正如上文所说,当前AI视频还未迎来自己的GPT时刻,因此竞争尚在早期。
参考文生图模型的迭代路径,尽管出现不少诸如Midjourney类的独角兽企业通过前期积累用户规模,快速商业化,实现营收,而建立起一定的壁垒。
因此,视频领域的竞争也会类似大语言模型的竞争格局。Pika的联创也提到:“我认为未来在视频领域也会是一家公司领先一到两年、在冲锋,其他公司在追赶。”
而在这样一个充满不确定的早期市场,较早出圈的也基本都是呈现极强PMF(Product-market fit,产品市场契合度)的玩家。
这之中,无论是专注在短视频内容AI口型匹配和翻译的HeyGen,抑或是如今爆火的Pika所呈现出的可编辑性和电影级效果,本质上也都是迅速找到与自己产品契合的市场。
仅用7个月时间达到了100万美元的ARR的HeyGen CEO&联合创始人徐卓在近期的分享文章中提到:“如果没有PMF时,技术都无关紧要。”
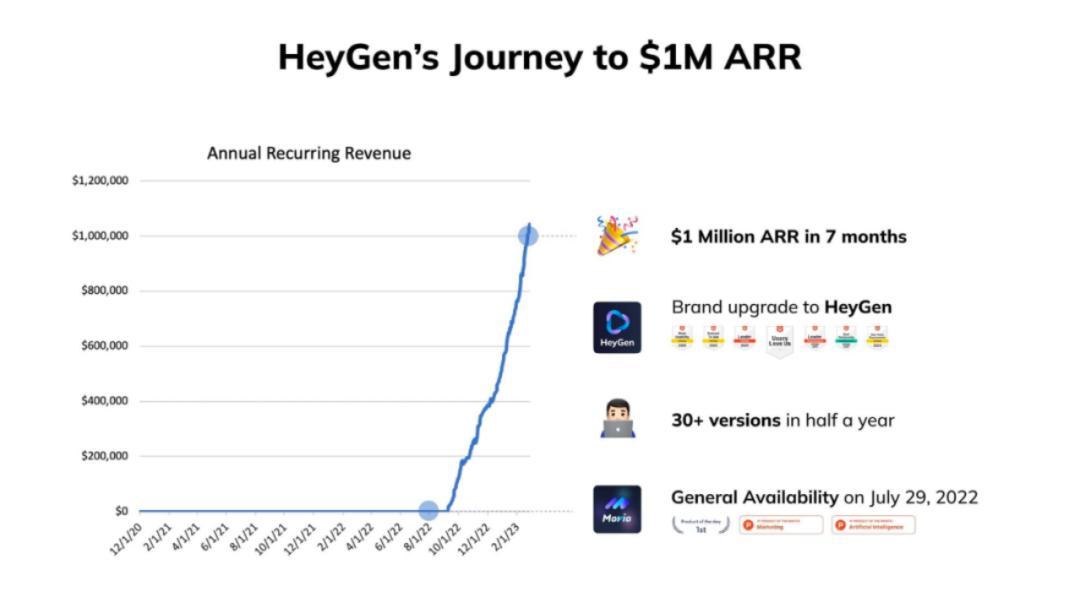
HeyGen用7个月时间达到了100万美元的ARR
某种程度上,这其实反映出了一个趋势:比起文生图的竞争,在更高门槛的AI视频,创业公司寻求商业化的意愿更强烈。
产生上述焦虑的原因也并不难理解。
一是算力的掣肘,视频领域对算力需求更高。 Pika联创就曾举过一个例子:“对于 Stable Diffusion,有人可能用8张A100就能从头开始学习,并得到不错的结果。但对于视频模型,用8张A100可能不够了,可能无法训练出一个好的模型。”
她甚至坦言,开源社区可能没有足够的算力来训练新的视频模型,除了一些大公司开源模型外,普通开源社区很难进行探索性工作。
二是竞争环境的激烈。 在AI视频产品层面,一方面正如上文所梳理的,头部科技巨头基本都已入局,只是产品尚未全面公测。另一方面,也包括了如Adobe此类面向专业级用户的老牌软件巨头和如已有先发优势的Runway。
还有一类则是HeyGen、Descript、CapCut类的轻量化视频制作产品。
大型科技公司具备算力优势,特别在是目前尚未有巨头明确开源路线(只有Stability AI发布了开源生成式视频模型Stable Video Diffusion)。而Adobe此类企业的优势在于AI视频功能和原有业务形成有力的协同,形成更高频的使用。Adobe此前也收购了一家AI视频领域的初创公司Rephrase.ai。
而轻量化的视频制作产品本身面向的是非专业人群,这意味着能否以差异化优势快速圈中人群,占据心智成为关键。
套用一句老生常谈,人们对技术的态度永远是高估短期,低估长期,AI视频也并不例外。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表本站立场。



